如果不了解JS混淆原理以及常见的混淆手段,可以戳我以前写过的2篇文章:JS代码安全防护原理——AST混淆原理 和 JS逆向之代码混淆的原理
开篇先回答一个问题,为什么需要反混淆?因为一般具有防护的JS代码都会经过混淆处理,虽然经过混淆的代码完全可以不处理混淆依旧对其进行逆向,但是由于字符串,数字都是混淆的,同时源码中冗余了很多无关的代码,控制流程平台化的存在更是让我们在代码的阅读上有了很大的障碍,这样下来导致逆向源码耗费的时间需要成倍的增加。如果有一种方式,能够让我们获得的源码就是高可阅读性,也没有冗余的代码,能帮我们不止一点点地提高逆向源码的效率,你学还是不学?
什么是AST?
所谓磨刀不误砍材功,既然反混淆是必要的,那跟AST有啥关系?不着急,容我慢慢解释。试想一下,要反混淆的话,是不是得处理JS源码?对于源码而言,如果只是一个文本文件,是不是非常不好处理(变量,常量,函数,分支什么的都是分散的)?所以我们必须把源码预处理成一种利于解混淆的形式,比如JSON格式?如果大学有接触过编译原理的话,一定有接触一个概念叫做语法树。没错,AST(Abstract Syntax Tree),中文抽象语法树,简称语法树(Syntax Tree),是源代码的抽象语法结构的树状表现形式,树上的每个节点都表示源代码中的一种结构。
让我们看看AST长啥样?打开AST提供的一个解析网站:https://astexplorer.net/ ,其顶部可以选择语言,编译器。语法树没有单一的格式,选择不同的语言、不同的编译器,得到的结果也是不一样的,在 JavaScript 中,编译器有 Acorn、Espree、Esprima、Recast、Uglify-JS 等,使用最多的是 Babel,后续的学习也是以 Babel 为例。如下图:
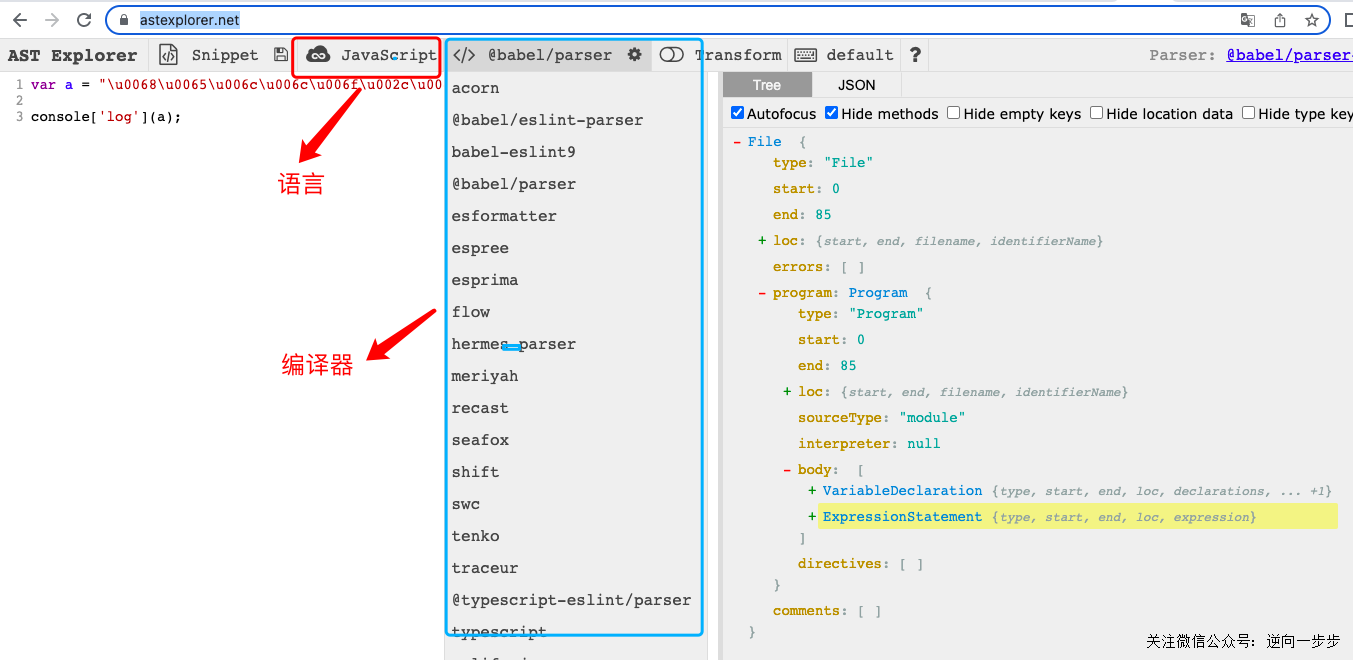
Babel简介
Babel 是一个 JavaScript 编译器,也可以说是一个解析库。Babel 内置了很多分析 JavaScript 代码的方法,我们可以利用 Babel 将 JavaScript 代码转换成 AST 语法树,然后增删改查等操作之后,再转换成 JavaScript 代码。
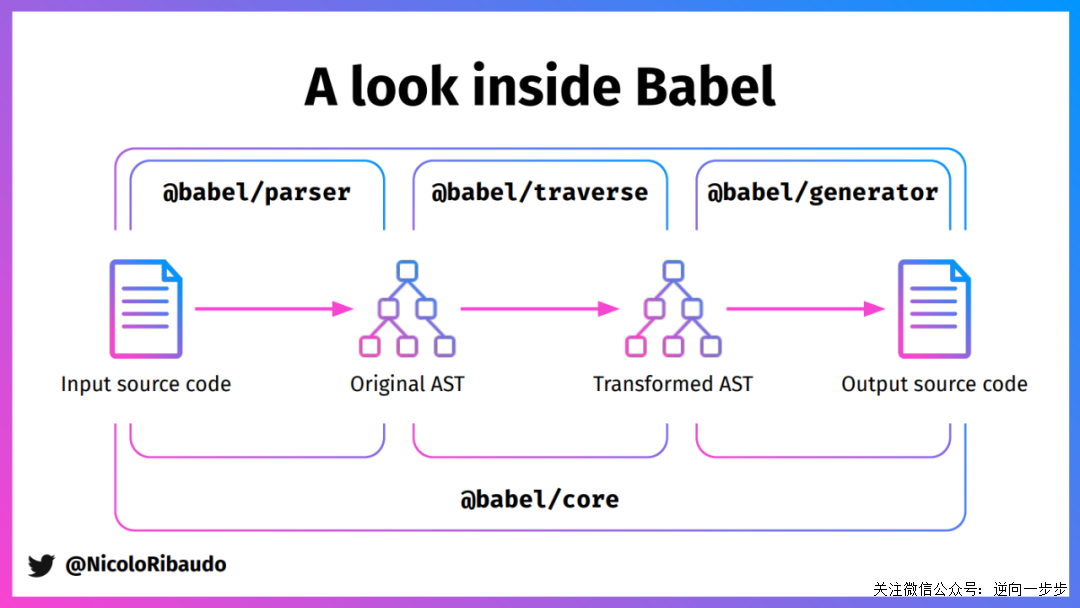
在做逆向解混淆中,主要用到了 Babel 的以下几个功能包,本文也仅介绍以下几个功能包:
@babel/core:Babel 编译器本身,提供了 babel 的编译 API;@babel/parser:将 JavaScript 代码解析成 AST 语法树;@babel/traverse: 遍历、修改 AST 语法树的各个节点;@babel/generator:将 AST 还原成 JavaScript 代码;@babel/types:判断、验证节点的类型、构建新 AST 节点等。
用一张图说明上面各个模块的功能:
babel库的安装
安装完NodeJS之后,使用命令npm install @babel/core进行安装即可。
@babel/core
Babel 编译器本身,被拆分成了三个模块:@babel/parser、@babel/traverse、@babel/generator,比如以下方法的导入效果都是一样的:
1 | const parse = require("@babel/parser").parse; |
@babel/parser
@babel/parser 可以将 JavaScript 代码解析成 AST 语法树,其中主要提供了两个方法:
parser.parse(code, [{options}]):解析一段 JavaScript 代码;parser.parseExpression(code, [{options}]):考虑到了性能问题,解析单个 JavaScript 表达式。
部分可选参数 options:
| 参数 | 描述 |
|---|---|
| allowImportExportEverywhere | 默认 import 和 export 声明语句只能出现在程序的最顶层,设置为 true 则在任何地方都可以声明 |
| allowReturnOutsideFunction | 默认如果在顶层中使用 return 语句会引起错误,设置为 true 就不会报错 |
| sourceType | 默认为 script,当代码中含有 import 、export 等关键字时会报错,需要指定为 module |
| errorRecovery | 默认如果 babel 发现一些不正常的代码就会抛出错误,设置为 true 则会在保存解析错误的同时继续解析代码,错误的记录将被保存在最终生成的 AST 的 errors 属性中,当然如果遇到严重的错误,依然会终止解析 |
好了,看完理论知识,来实践下:
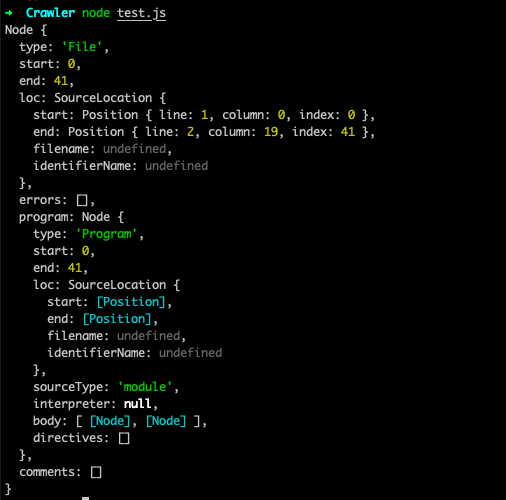
1 | const parser = require("@babel/parser"); |
执行,结果如下,可以看到跟在 https://astexplorer.net/ 中看到的是一致的。
@babel/generator
@babel/generator 可以将 AST 还原成 JavaScript 代码,提供了一个 generate 方法:generate(ast, [{options}], code)。
部分可选参数 options:
| 参数 | 描述 |
|---|---|
| auxiliaryCommentBefore | 在输出文件内容的头部添加注释块文字 |
| auxiliaryCommentAfter | 在输出文件内容的末尾添加注释块文字 |
| comments | 输出内容是否包含注释 |
| compact | 输出内容是否不添加空格,避免格式化 |
| concise | 输出内容是否减少空格使其更紧凑一些 |
| minified | 是否压缩输出代码 |
| retainLines | 尝试在输出代码中使用与源代码中相同的行号 |
我们运行一段下面的代码:
1 | const parser = require("@babel/parser"); |
最终输出结果var b="Hello";,变量名和值都成功更改了,由于加了压缩处理,等号左右两边的空格也没了。
代码里 {minified: true} 演示了如何添加可选参数,这里表示压缩输出代码,generate 得到的 result 得到的是一个对象,其中的 code 属性才是最终的 JS 代码。
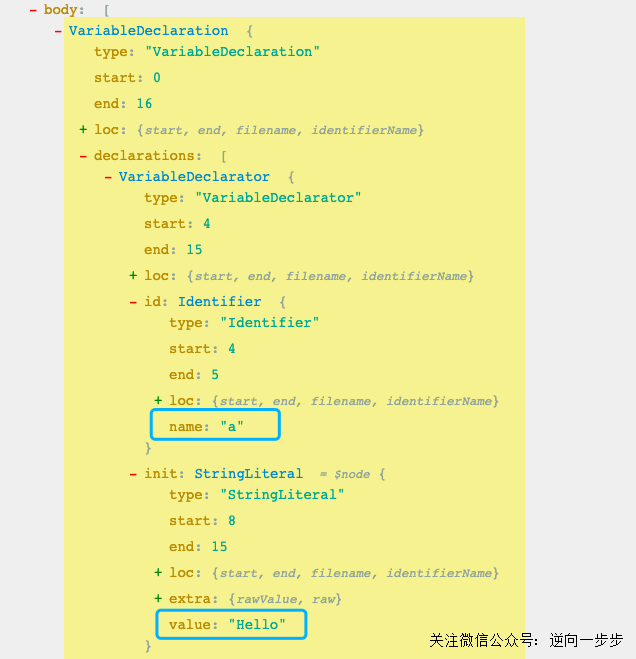
代码里 ast.program.body[0].declarations[0].id.name 是 a 在 AST 中的位置,ast.program.body[0].declarations[0].init.value 是 a的值即字符串Hello 在 AST 中的位置,如下图所示:
@babel/traverse
当代码多了,我们不可能像前面那样挨个定位并修改,对于相同类型的节点,我们可以直接遍历所有节点来进行修改,这里就用到了 @babel/traverse,它通常和 visitor 一起使用,visitor 是一个对象,这个名字是可以随意取的,visitor 里可以定义一些方法来过滤节点,这里还是用一个例子来演示:
1 | const parser = require("@babel/parser"); |
输出为var b="I Love JavaScript!";,通过AST语法树,将变量a更名为变量b,同时将其值修改为”I Love JavaScript!”。
我们看看代码主逻辑,首先定义一个visitor,然后定义对应类型的处理方法,traverse 接收两个参数,第一个是 AST 对象,第二个是 visitor,当 traverse 遍历所有节点,遇到节点类型为 StringLiteral 和 Identifier 时,就会调用 visitor 中对应的处理方法。 之所以定义StringLiteral和Identifier两种类型,是因为在抽象语法树中变量a是一个标识符,其类型为Identifier,而a的值是一个字符串,其类型为StringLiteral。visitor 中的方法会接收一个当前节点的 path 对象,该对象的类型是 NodePath,该对象有非常多的属性,以下介绍几种最常用的:
| 属性 | 描述 |
|---|---|
| toString() | 当前路径的源码 |
| node | 当前路径的节点 |
| parent | 当前路径的父级节点 |
| parentPath | 当前路径的父级路径 |
| type | 当前路径的类型 |
path 对象除了有很多属性以外,还有很多方法,比如替换节点、删除节点、插入节点、寻找父级节点、获取同级节点、添加注释、判断节点类型等,可在需要时查询相关文档或查看源码,后续介绍 @babel/types 部分将会举部分例子来演示,以后的实战文章中也会有相关实例。
如果多个类型的节点,处理的方式都一样,那么还可以使用 | 将所有节点连接成字符串,将同一个方法应用到所有节点:
1 | const visitor = { |
visitor 对象有多种写法,以下几种写法的效果都是一样的:
1 | const visitor = { |
以上几种写法中有用到了 enter 方法,在节点的遍历过程中,进入节点(enter)与退出(exit)节点都会访问一次节点,traverse 默认在进入节点时进行节点的处理,如果要在退出节点时处理,那么在 visitor 中就必须声明 exit 方法。
@babel/types
前面提到过,babel/types主要2个作用,一是包含了许多节点的类型,经常用来做类型判断。比如:
1 | types.stringLiteral("Hello World"); // string |
输出如下:
1 | "Hello World" |
另一个作用是构建新的 AST 节点。通过一个简单的例子解释下吧。比如我们有如下代码
1 | const a="Hello"; |
想在这句常量的定义之后插入let b=1; 这段代码,变成如下:
1 | const a="Hello"; |
我们在 https://astexplorer.net/ 中输入这2行代码,然后对照着看下代码该如何写?

可以看到增加了一个变量声明之后,会在body下面增加一个VariableDeclaration节点。所以我们编写visitor的时候,相应的代码也应该在VariableDeclaration下面。
我们的思路就是在遍历节点时,遍历到 VariableDeclaration 节点,就在其后面增加一个 VariableDeclaration 节点,生成 VariableDeclaration 节点,可以使用 types.variableDeclaration() 方法,在 types 中各种方法名称和我们在 AST 中看到的是一样的,只不过首字母是小写的,所以我们不需要知道所有方法的情况下,也能大致推断其方法名,只知道这个方法还不行,还得知道传入的参数是什么,可以查文档。
通过文档,可以看到variableDeclarator需要kind 和 declarations 两个参数,其中 declarations 是 VariableDeclarator 类型的节点组成的列表。kind表示声明的类型,比如const, var, let。这里顺便问下为什么declarations是一个列表呢?因为JS是支持同时声明多个变量的,比如let a, b, c = 1,显然,declarations有多个。
接下来我们还需要进一步定义 declarator,也就是 VariableDeclarator 类型的节点。调用的是variableDeclarator方法,这个方法接受2个参数,第一个是类型,我们传入types.identifier("b"),表示一个名为b的标识符,第二个参数是变量的初始化方式,这里我们传入types.numericLiteral(1),因为我们是要给b赋值一个数值类型1。
最后我们要指明这条赋值表达式的插入位置,path.insertAfter() 插入节点语句后面加了一句 path.stop(),表示插入完成后立即停止遍历当前节点和后续的子节点,添加的新节点也是 VariableDeclaration,如果不加停止语句的话,就会无限循环插入下去。
完整的代码如下:
1 | const parser = require("@babel/parser"); |
小案例
最后通过一个小案例来为这篇入门文章结尾吧。
我们有如下一段代码:
1 | var a = "\x44\x61\x74\x65"; |
这些数字或者字符串看起来非常不方便,所以我们需要对其进行解混淆处理,解混淆代码如下:
1 | const parser = require("@babel/parser"); |
解混淆结果如下:


