为什么使用CSS做反爬
- 成本低
- 只需要前段混淆样式
- 不需要复杂的加密技术
- 不需要验证码,流量检测等额外配置
因此,对于企业来说,仅仅用一些CSS技巧就可以防住爬虫,可以不需要投入很多资源,这样会节省资金以及时间资源。
- 效果好
- 难以识别
- 抓取内容与预期内容相近,容易误导爬虫工程师
- 反爬措施不容易发觉
- 可以混淆竞争对手
- 没有成熟的破解套路
- 破解CSS混淆的反爬措施需要想象力
- 没有统一的破解套路,需要人工干预
用CSS的反爬效果好,所以企业可以花很少的时间成本来获取较大的反爬效益,这种措施显得尤为具有吸引力。
CSS反爬类别
图片伪装反爬虫
图片伪装指的是将带有文字的图片与正常文字混合在一起,以达到“鱼目混珠”的效果。这种混淆方式并不会影响用户阅读,但是可以让爬虫程序无法获得“所见”的文字内容。图片反爬虫通常会将一些关键信息以图片的形式展示出来。
举例
网址:aHR0cHM6Ly93d3cuZ3hyYy5jb20vY29tcGFueS9hYmFmMjU1Yy1mZjE3LTQ2YjAtOWM0Zi03YzkyOTZiY2FmMTc=,把电话信息通过图片的形式展示,如下:
对于这种图片的文字提取,需要用到光学字符识别技术OCR。
推荐几个好用的OCR库:
本来想用PaddleOCR来进行文字提取的,但是我用的是MacOS M1芯,安装的时候有各种问题,所以这里也先不折腾,就用了EasyOCR进行识别,识别结果如下:
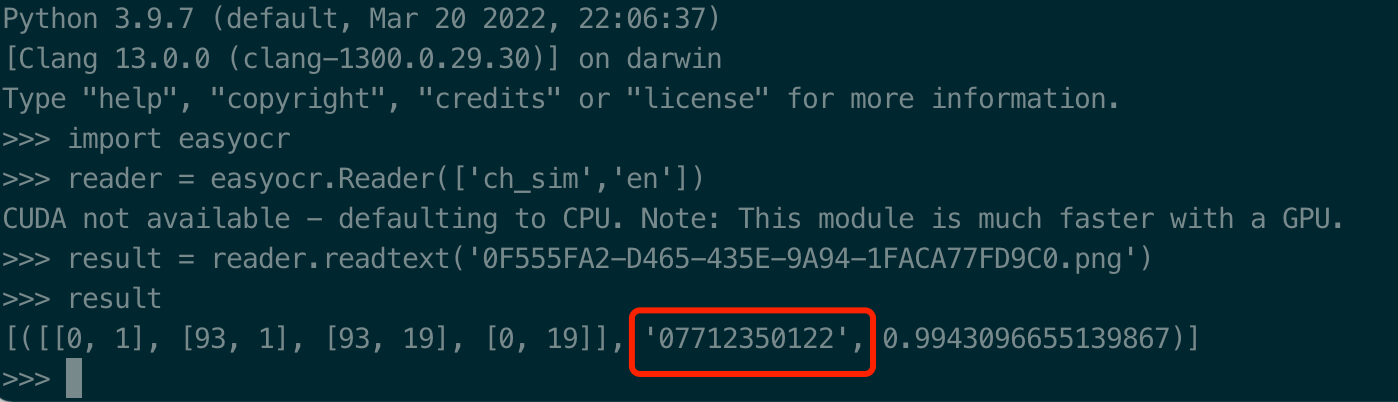
虽然爬虫工程师可以借助渲染工具获得页面渲染后的网页文本,但爬虫无法直接从图片这种媒体文件中获取字符。光学字符识别技术也有一定的缺陷,在面对扭曲文字、生僻字和有复杂干扰信息的图片时,它就无法发挥作用了。
利用字体反爬虫
字体反爬原理:
- 主要利用了font-family这个属性,例如设置为my-font
- 在HTML里不常见的unicode
- 在CSS的字体中将其映射到常见的(可读的)字体,例如数字
- 爬虫在抓取数据的时候只能抓到unicode,而不是真实的数据
解决方案:
- 下载woff字体文件,转为tff文件
- 用百度字体编辑器打开,并确定其unicode与实际的映射关系
- 将下载的HTML内容按照映射关系进行替换
- 解析HTML并获取正确的数据
难点:
- 有些网站会动态的生成woff,这种反爬措施比较难以自动化绕开
举例
网址:aHR0cHM6Ly9jbHViLmF1dG9ob21lLmNvbS5jbi9iYnMvdGhyZWFkL2QxNzUxYzdiZDA1MzlkZTAvNzkyMjk2NjgtMS5odG1s,部分文字以特殊字体展示,如图:
我们通过抓包,拿到对应的字体文件,然后用百度文字编辑器打开:
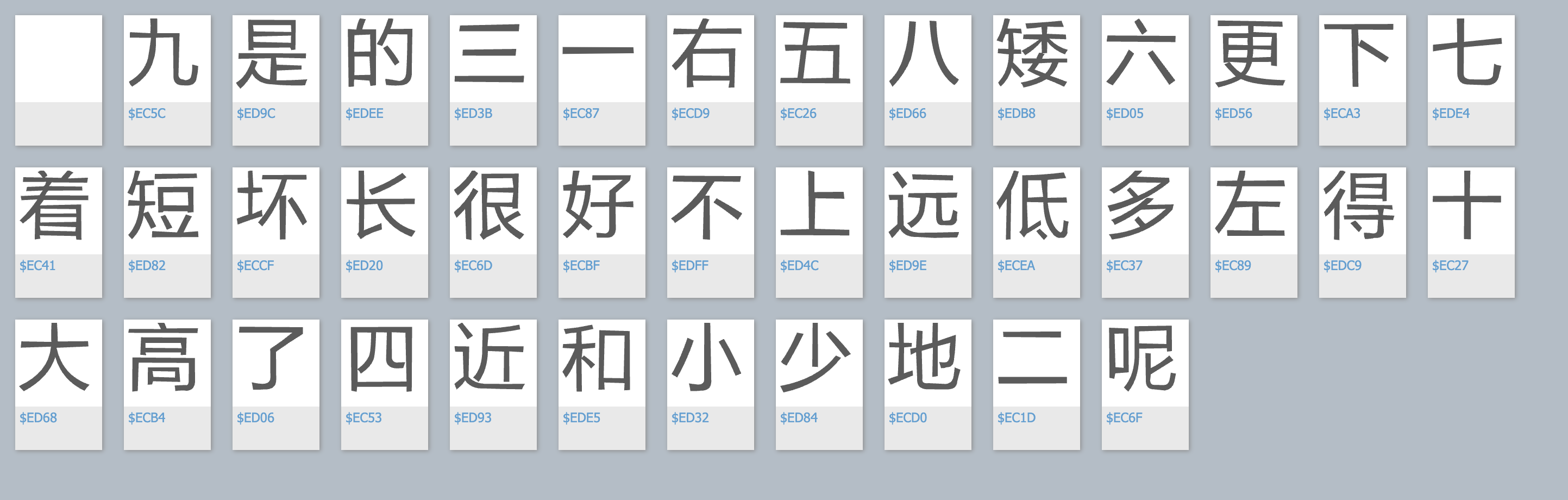
拷贝大字对应的那一个奇怪的字符,转为unicode编码,如图:

可以看到ed68正好对应上边的$ED68这个汉子,即大。这个网站的字体是动态加载的,每次使用特殊字体的汉子是随机的,增加了反爬的难度。
CSS偏移反爬虫
CSS 偏移反爬虫指的是利用 CSS 样式将乱序的文字排版为人类正常阅 读顺序的行为。这个概念不是很好理解,我们可以通过对比两段文字 来加深对这个概念的理解:
HTML 文本中的文字:我的学号是 1308205,我在北京大学读书。
浏览器显示的文字:我的学号是 1380205,我在北京大学读书。
爬虫提取到的学号是 1308205,但用户在浏览器中看到的却是 1380205。如果不细心观察,爬虫工程师很容易被爬取结果糊弄。这种混淆方法和图片伪装一样,是不会影响用户阅读的。让人好奇的是浏览器如何将 HTML 文本中的数字按照开发者的意愿排序或放置呢? 这种放置规则是如何运作的呢?
举例
网址:http://www.porters.vip/confusion/flight.html#
可以看到航班机票不能直接拿到,而是用到CSS偏移:
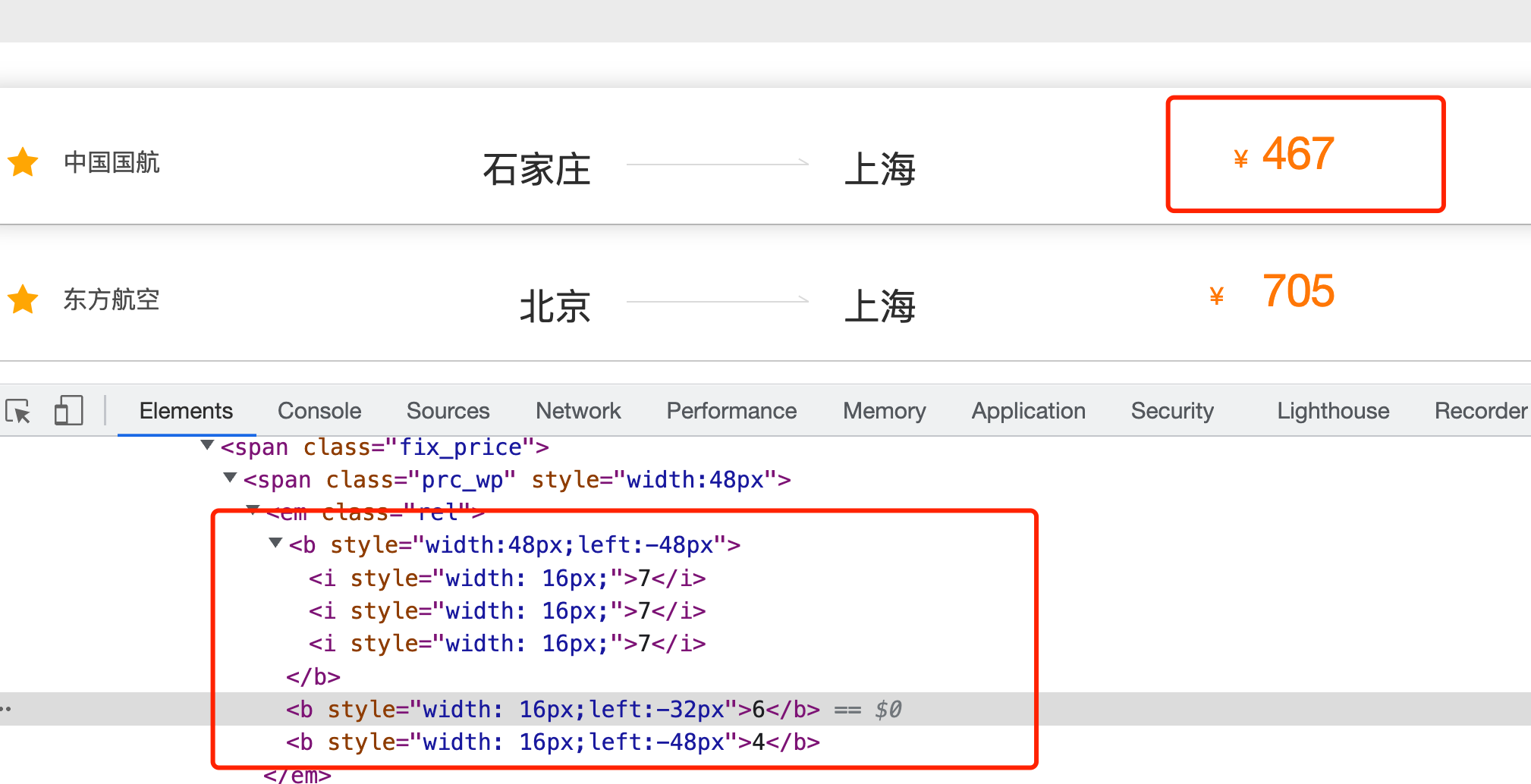
我们可以看出规律,77764排成一列,每个宽度为16px,然后6这个数字左偏移32px就变成了76774,4这个数字向左偏移64个px就变成了46777,由于设置展示宽度为48px,所以只看到前三个数字,就刚好是467。
利用伪类反爬虫
反爬原理:
- 不直接将内容展现到html的元素中
- 通过伪类的content属性将要展示的值展示出来。
例如:鼠标悬浮的时候展示数据
解决方案:
- 利用playwright或者pyppeteer这样的自动化测试工具
- 在页面上执行下面的JS代码,即可获取content。注意:before是伪类,也可能是after。
1 | const el = document.querySelector("类选择器") |
利用字符切割反爬虫
反爬原理:
- 将字符串用标签分割
- 由于是内联块级(inline-block),可以一行展示
- 通常还混淆有不现实的标签(display:none)
解决方案:
- 将内联块级标签的innerText拼接起来
- 注意过滤掉所有的display:none的属性
SVG映射反爬虫
SVG 是用于描述二维矢量图形的一种图形格式。它基于 XML 描述图 形,对图形进行放大或缩小操作都不会影响图形质量。矢量图形的这 个特点使得它被广泛应用在 Web 网站中。
SVG反爬虫手段用矢量图形代替具体的文字,不会影响用户正常阅读,但爬虫程序 却无法像读取文字那样获得SVG图形中的内容。由于 SVG中的图形代表的也是一个个文字,所以在使用时必须在后端或前端将真实的文字与对应的SVG图形进行映射和替换,这种反爬虫手段被称为SVG映射反爬虫。
举例:
网址:http://www.porters.vip/confusion/food.html
可以看到,很多数字在原始HTML页面中都没有,而是以标签形式出现,如下图:
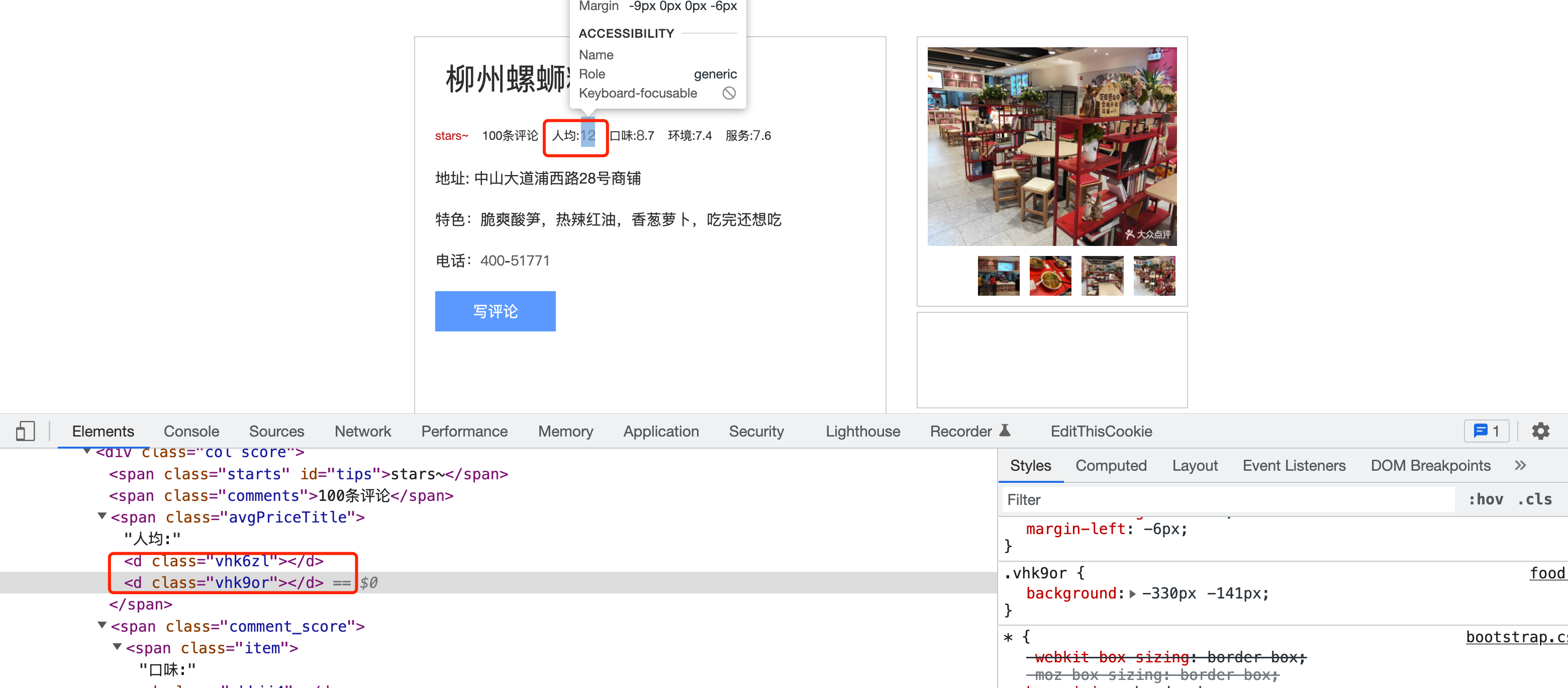
而商家电话号码处的显示就更奇怪了,一 个数字都没有。商家电话对应的 HTML 代码如下:
1 | <div class="col more">电话: |
我们推测它是用d标签来占位代表一个数字,通过class属性来区分代表数字的含义。我们通过页面上已经展示的数字,来建立一个映射关系,如下:
1 | <d class="vhk08k"></d> <!-- 0 --> |
那剩余的几个数字如3,6,9到哪里去找呢?既然是通过class区分,那么class的样式肯定会在CSS文件中有定义。
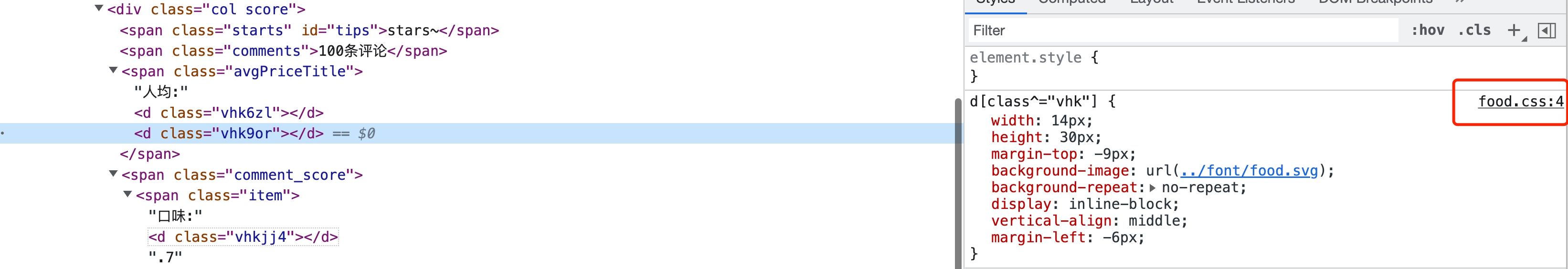
我们去CSS文件中找,果然找到了以下代码:
1 | .vhk08k { |
从上到下依次与我们上边推断的几个数字相对应,因此,判定<d class="vhkfln"></d>对应数字3,<d class="vhkvxd"></d>对应数字6,<d class="vhk0f1"></d>对应数字9。至此,就破解了全部的数字了。
总结
本文简单介绍了几种常见的CSS反爬,然后举了一些简单的例子加以分析,并没有涉及太多的代码层面,而且涉及到的知识也比较浅显,只是浅尝则止。因为本文是作为CSS反爬的开篇内容,后边会有专门的文章,利用更常见的网站,难度更大的网站,去深入分析每一种CSS反爬。

