比如有下面一段代码:
1 | m7z = { |
这种把字符串处理成unicode或者utf8编码,把数字处理成非10进制,不利于我们进行调试,我们可以对其进行反混淆,变成我们更加习惯的编码或者进制。
观察AST结构:

image-20220630155927641

image-20220630160915492
可以看到在extra节点中的raw是utf-8编码的,而value的值是正常的。官网手册查询得知,NumericLiteral、StringLiteral类型的extra节点并非必需,这样在将其删除时,不会影响原节点。所以一种通用的解决方案是直接删除extra节点即可。
所以解混淆插件代码如下:
1 | const visitor = |
遍历遇到NumericLiteral节点时,判断extra是否为二进制,八进制,十六进制,如果是的话直接置空;同理,遍历遇到StringLiteral节点时,判断其extra是否为unicode编码或者utf8编码,如果是的话也置空。
最后解混淆的结果如下:
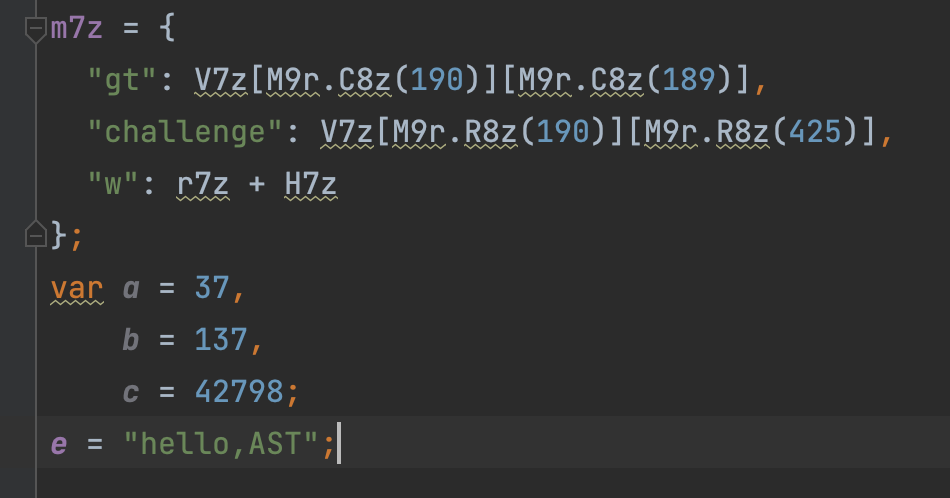
image-20220630161728547

