_ = list(map(lambda x: print(f"ascii of {x} is", ord(x)), "abcd")) # ascii of a is 97 # ascii of b is 98 # ascii of c is 99 # ascii of d is 100
Base64
什么是Base64
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。
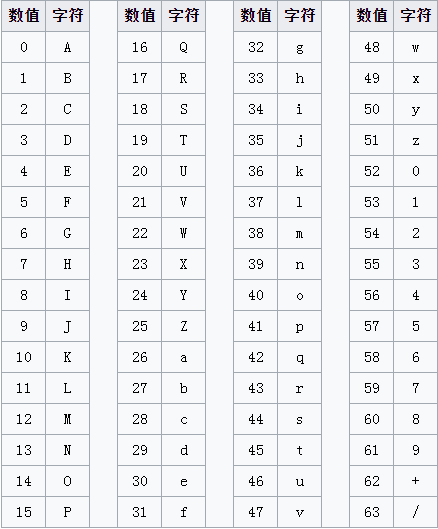
Base64的字符集
数字 {0, 1, 2, 3, 4, 5, 6, 7, 8, 9} 共10位
大小写字母 {A, B, C, D, E, F, G, H, I, J, K, L, M, N, O, P, Q, R, S, T, U, V, W, X, Y, Z, a, b, c, d, e, f, g, h, i, j, k, l, m, n, o, p, q, r, s, t, u, v, w, x, y, z} 共52位
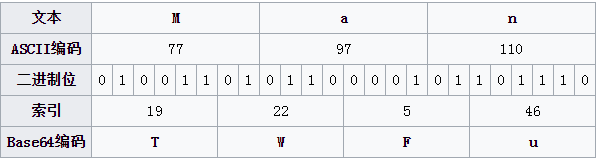
integral_part = base64_bytes[0:3 * nums] while integral_part: # 取三个字节,以每6比特,转换为4个整数 tmp_unit = ''.join(integral_part[0:3]) tmp_unit = [int(tmp_unit[x: x + 6], 2) for x in [0, 6, 12, 18]] # 取对应base64字符 resp += ''.join([base64_charset[i] for i in tmp_unit]) integral_part = integral_part[3:]
if remain: # 补齐三个字节,每个字节补充 0000 0000 remain_part = ''.join(base64_bytes[3 * nums:]) + (3 - remain) * '0' * 8 # 取三个字节,以每6比特,转换为4个整数 # 剩余1字节可构造2个base64字符,补充==;剩余2字节可构造3个base64字符,补充= tmp_unit = [int(remain_part[x: x + 6], 2) for x in [0, 6, 12, 18]][:remain + 1] resp += ''.join([base64_charset[i] for i in tmp_unit]) + (3 - remain) * '='
# 对每一个base64字符取下标索引,并转换为6为二进制字符串 base64_bytes = ['{:0>6}'.format(str(bin(base64_charset.index(s))).replace('0b', '')) for s in base64_str if s != '='] resp = bytearray() nums = len(base64_bytes) // 4 remain = len(base64_bytes) % 4 integral_part = base64_bytes[0:4 * nums]
while integral_part: # 取4个6位base64字符,作为3个字节 tmp_unit = ''.join(integral_part[0:4]) tmp_unit = [int(tmp_unit[x: x + 8], 2) for x in [0, 8, 16]] for i in tmp_unit: resp.append(i) integral_part = integral_part[4:]
if remain: remain_part = ''.join(base64_bytes[nums * 4:]) tmp_unit = [int(remain_part[i * 8:(i + 1) * 8], 2) for i inrange(remain - 1)] for i in tmp_unit: resp.append(i)
functiondecrypt(text) { var result = CryptoJS.AES.decrypt(text, CryptoJS.enc.Utf8.parse(key), { iv: '', mode: CryptoJS.mode.ECB, padding: CryptoJS.pad.Pkcs7 }); return result.toString(CryptoJS.enc.Utf8); }
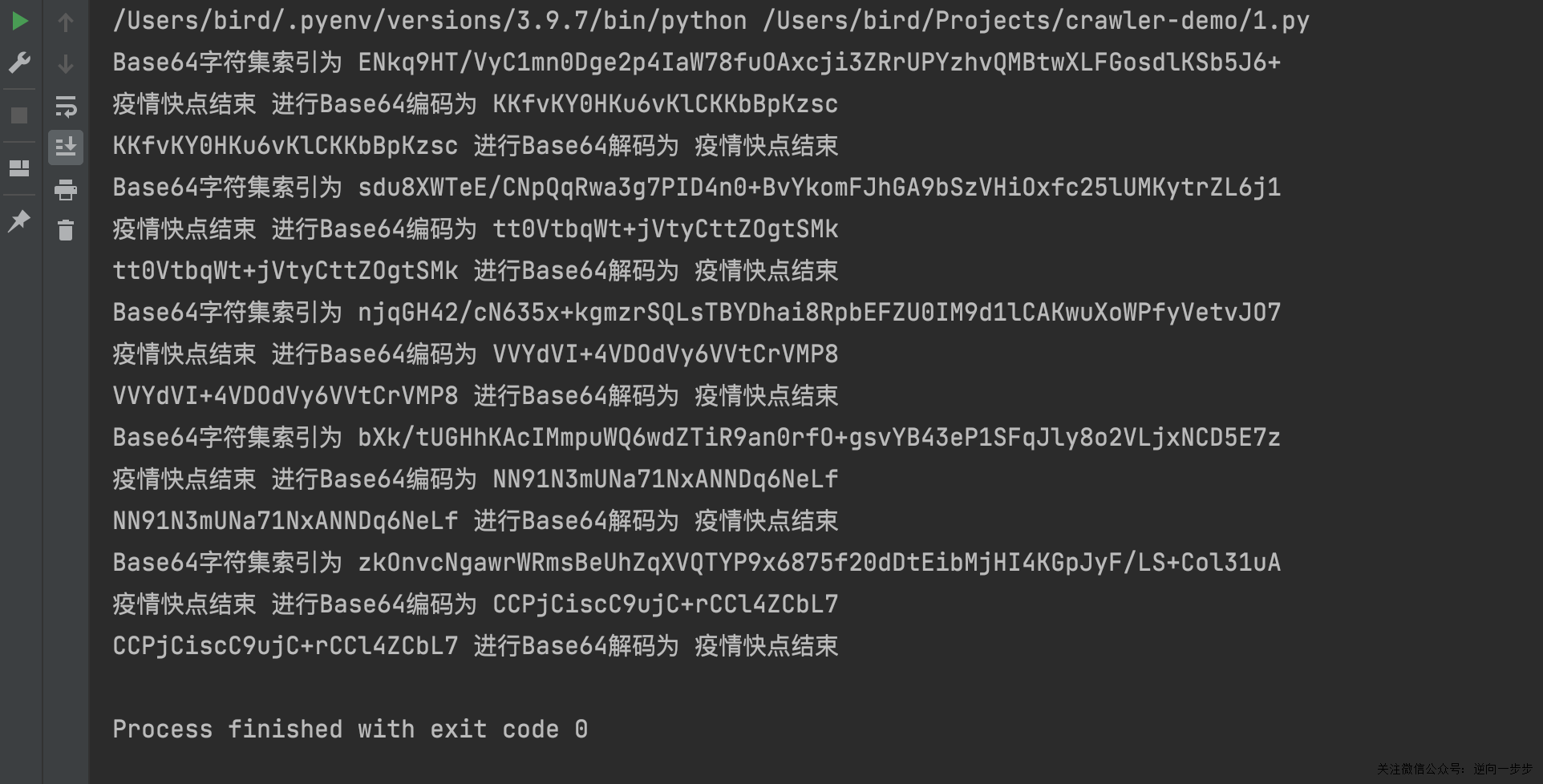
var text = "123456"; var encoded = encrypt(text); console.log(encoded.toString()); // nWhAGHyLGTLV1dff9+PEUw== console.log(decrypt(encoded)); // 123456
functiondecrypt(text) { var result = CryptoJS.AES.decrypt(text, CryptoJS.enc.Utf8.parse(key), { iv: CryptoJS.enc.Utf8.parse(iv), mode: CryptoJS.mode.CBC, padding: CryptoJS.pad.Pkcs7 }); return result.toString(CryptoJS.enc.Utf8); }
var text = "123456"; var encoded = encrypt(text); console.log(encoded.toString()); // 6S3YRylMmp9vIFOplWxypw== console.log(decrypt(encoded)); // 123456
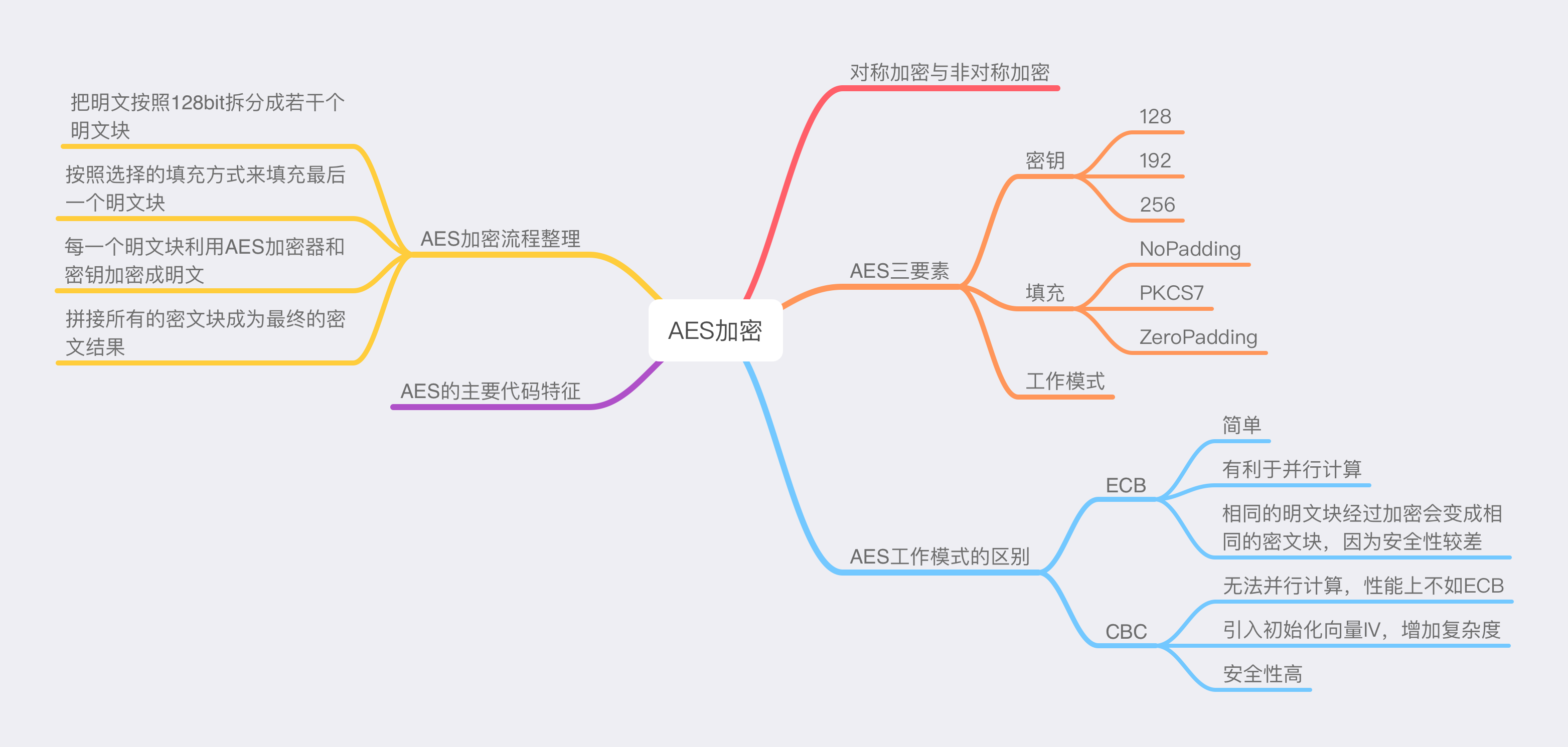
AES加密流程总结
把明文按照128bit拆分成若干个明文块。
按照选择的填充方式来填充最后一个明文块。
每一个明文块利用AES加密器和密钥加密成明文。
拼接所有的密文块成为最终的密文结果。
总结
AES加密
Last updated:
关注微信公众号~~逆向一步步~~,第一时间获取更新文章的推送 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!