免责声明:本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
关于无限debugger
在进入无限debugger之前先看下三个问题。
在什么情况下会遇到debugger
在分析网络请求,查看元素的事件监听器,跟踪JS等需求下,第一步就是打开浏览器的开发者工具,而打开浏览器工具就可能会碰到无限debugger死循环,或者在我们的调试过程中也可能出现无限debugger。
为什么反爬虫会用到debugger
因为分析代码逻辑,调试JS代码是JS逆向的必要手段,而分析调试则需要使用开发者工具。然后就可以在关键的地方设防,精准的设置第一道防线。
debugger反爬的优势在哪
实现比较简单,前端工程师可以不会写那种复杂的反人类的反爬代码,但是写个无限debugger是个基本操作。
效果比较明显,如果第一步都没法通过的话,就不会有下一步了。
一定程度上可以提高代码的安全性,可以阻止我们调试分析代码逻辑。
接下来正式进入无限debugger
常见无限debugger及解决方案
- 按代码逻辑划分
- 无限循环,比如for/while循环里面包含debugger关键字
- 无限递归,一个方法包含debugger关键字,并且递归调用自己
- 两个方法互调,两个方法彼此都包含debugger关键字,然后彼此调用彼此。
- 定时器,使用定时器执行一个方法,方法里面包含debugger关键字,就会定时执行debugger。
- 按是否混淆划分
- 直接在方法中使用debugger关键字或者通过eval执行,比如eval(“debugger”)
- 重度混淆,通过对debugger字符串进行混淆,然后使用eval执行,从而在全局搜索中搜索不到debugger关键字。
1 | Function("debugger").call()/apply() 或赋值 bind() |
- 其它的方式
debugger关键字贯穿整个JS文件。
处理无限debugger的几种方式
- 去除断点
这种情况针对debugger关键字比较少,可以选中debugger关键字的行号,鼠标右键添加conditional breakpoint,即添加条件断点,然后条件设置为false;也可以鼠标右键设置never pause here,即永远不会在此行暂停,这样也可以跳过这个debugger。
- 替换debugger关键字
如果debugger关键字非常多,贯穿多个JS文件,这时候一个个手动去除断点就显得非常麻烦了,这时候我们考虑保存相应的JS文件到本地,然后全局替换里面的debugger关键字,比如说把debugger关键字替换为false或者替换成debugger字符串,然后通过JS逆向之Chrome浏览器工具你知多少?介绍的override面板,把相应的请求代理到本地文件,或者说通过JS逆向之Charles工具篇介绍的Chares,利用其反向代理,也可以达到同样的目的,这样就可以屏蔽debugger关键字了。
- hook某些方法
手动置空包含debugger关键字的方法或者重写这个方法,这样做的前提是这个方法里面不包含有效的业务逻辑,不然虽然去除了无限debugger,但是相应的业务逻辑被修改了,导致我们无法调试正确的结果。
1 | xxx = function() {} |
案例分析
某气网
网址:aHR0cHM6Ly93d3cuYXFpc3R1ZHkuY24vaGlzdG9yeWRhdGEvZGF5ZGF0YS5waHA/Y2l0eT0lRTYlOUQlQUQlRTUlQjclOUUmbW9udGg9MjAyMjAy
打开浏览器输入网址然后本打算按照往常调出开发者工具,结果
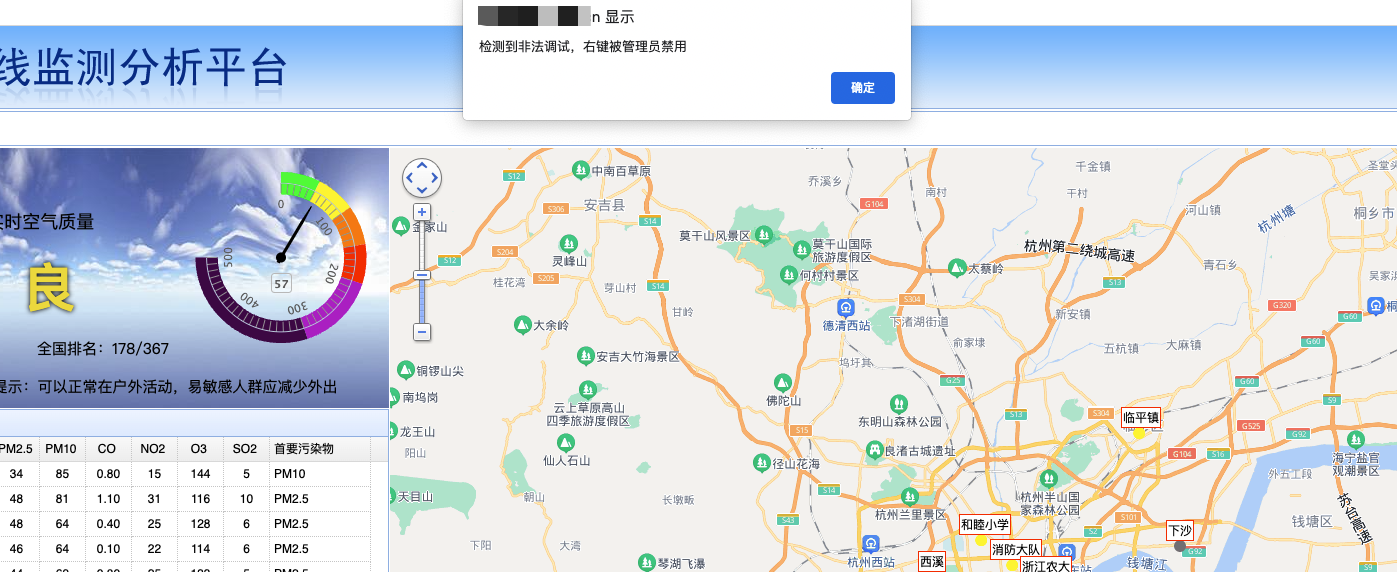
😮有意思,第一次遇到这样的网站,google了下遇到这种情况,首先打开一个空的tab,调出开发者工具,然后再输入网址,发现成功断上了。
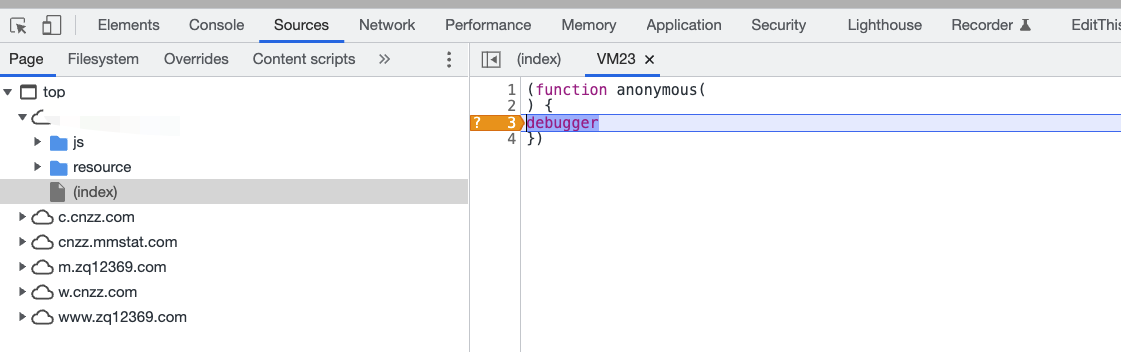
这里就出现了一个无限debugger,右键第三行然后选择Never pause here,接着往下调试:
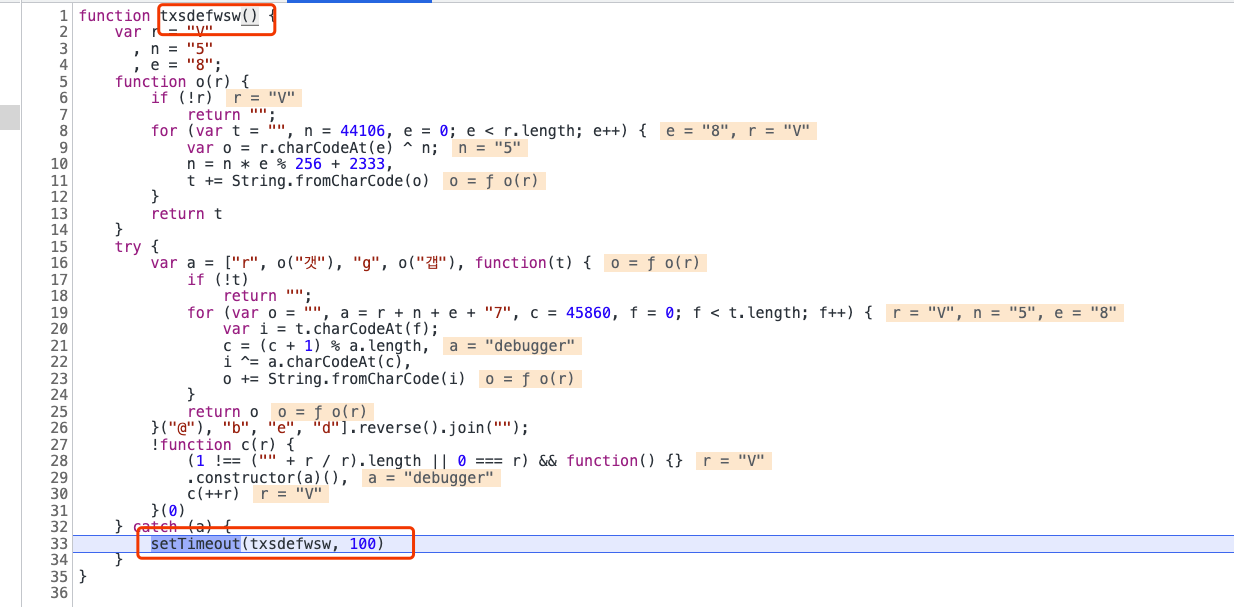
又出现了一个无限debugger,递归调用自己。我们在console控制台,把txsdefwsw这个方法置空:
1 | txsdefwsw = function() {} |
接着往下调试,接着又遇到一系列的检测:
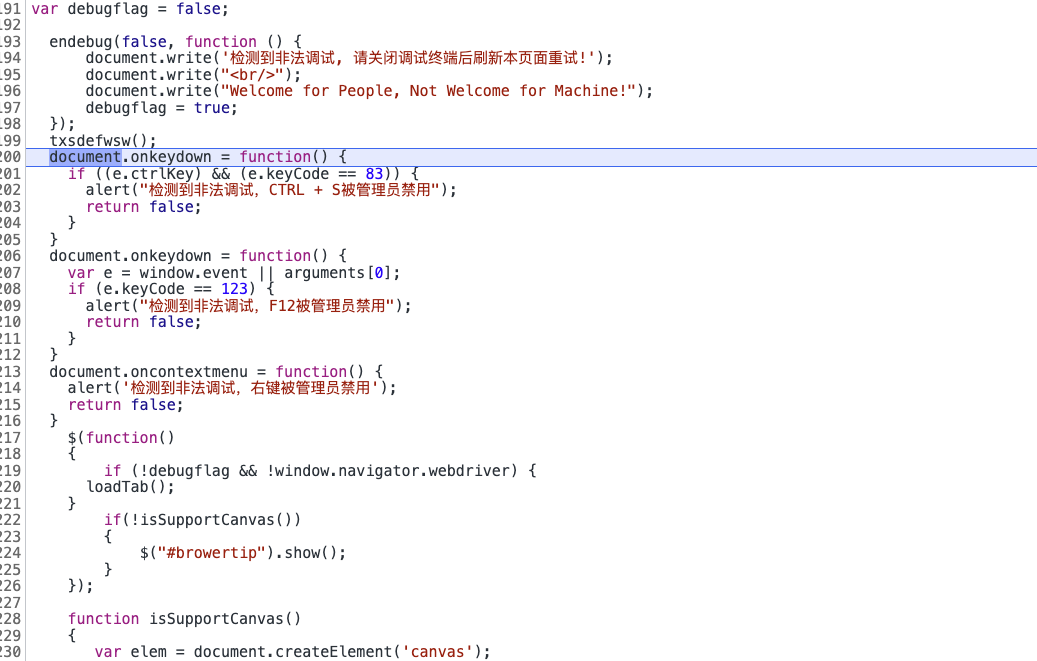
我们依次把方法重写:
1 | endebug = function(off, code) {} |
接着往下调试,会发现有一段代码通过检测窗口的outerHeight与innerHeight的差值判断是否打开了开发者工具:

这里我们把window.innerHeight设置为1200。上边还有一个检测时间差值的我们重写这个getTime方法:
1 | window.innerHeight = 1400 |
综合以上的分析,我们可以利用JS逆向之Tampermonkey工具篇介绍的油猴插件,更加方便的进行代码分析,油猴插件脚本内容如下:
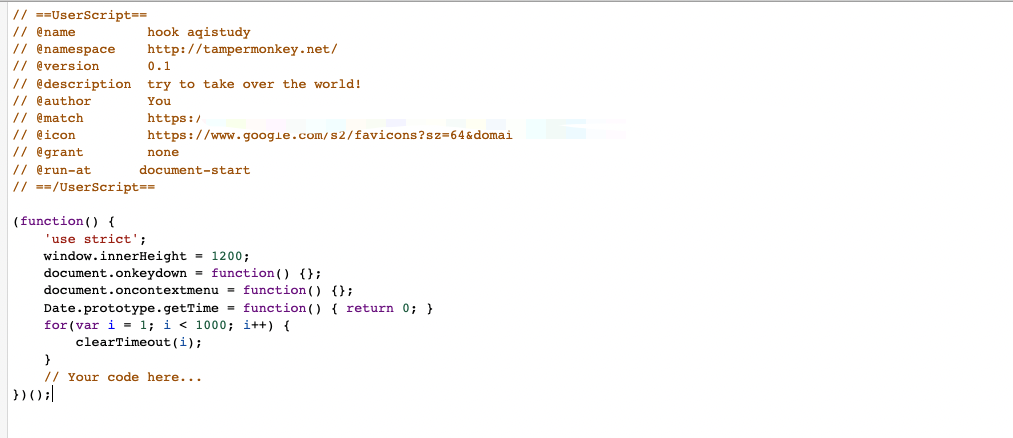
解释下上面for循环代码的含义,由于前面我们提到的无论是txsdefwsw还是endebug方法,都是通过匿名定时器来实现无限debugger的,匿名定时器无法根据定时器的名字来取消定时器,但是定时器的id基本都是1~1000,所以我们穷举这1000个id暴力取消这些匿名定时器。这不妨也是一种小技巧。
启用之后,我们刷新页面,就可以看到页面上已经加载出来数据了:
我们再来分析网络请求,看看能否抓取到数据包。没有发现XHR请求。

我们找到一个daydata.php的请求,然后里面有2个通过eval计算字符串的代码,如上图。我们在当前html页面并没有找到dUHTtbN9Om和dwDMxkUh0FG方法,那就很明显这两个方法在其它的JS文件里面,我们查看下这个html页面看看它引入了哪些JS文件,找到一个可疑的js文件de8qI5LXFNehN.min.js,我们找到这个文件,查看其内容:

然后用eval执行,得到文件内容如下:
我们阅读下代码,发现以下几点:
- 里面有一个Ajax请求是获取数据的。
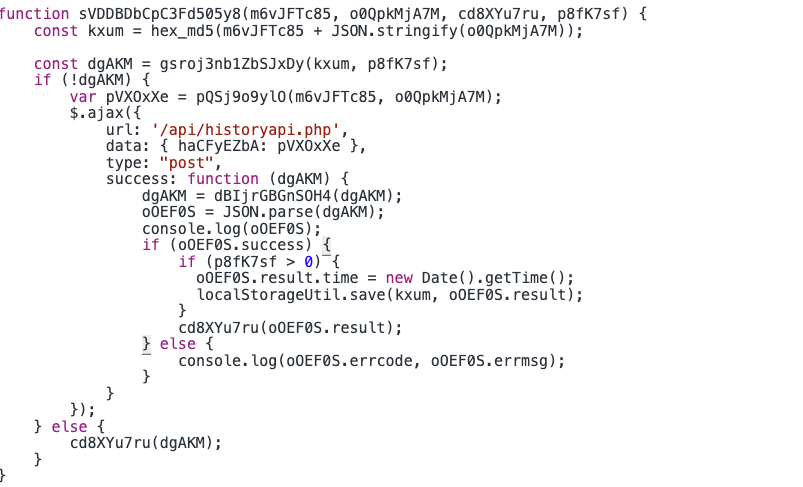
- 有一段读取本地缓存的逻辑,如果读取本地缓存没有数据然后再发Ajax请求去获取数据:
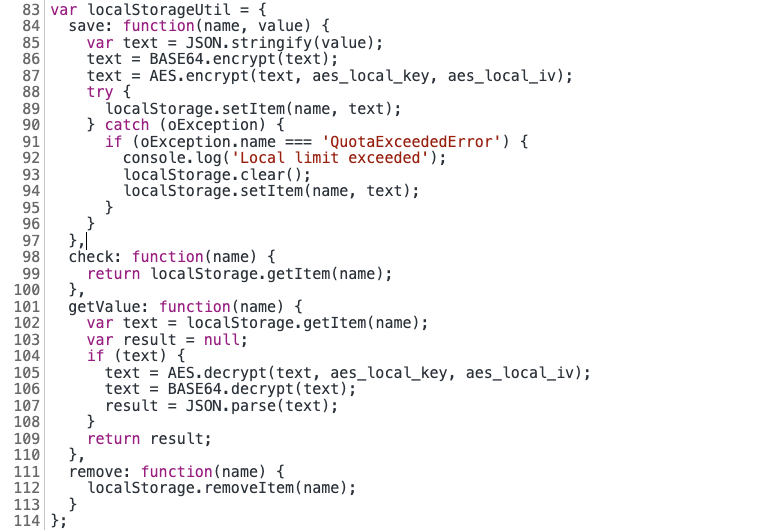
这也就解释了之前为啥没有XHR请求,只是有一个php请求,我们删除localStorage测试下:
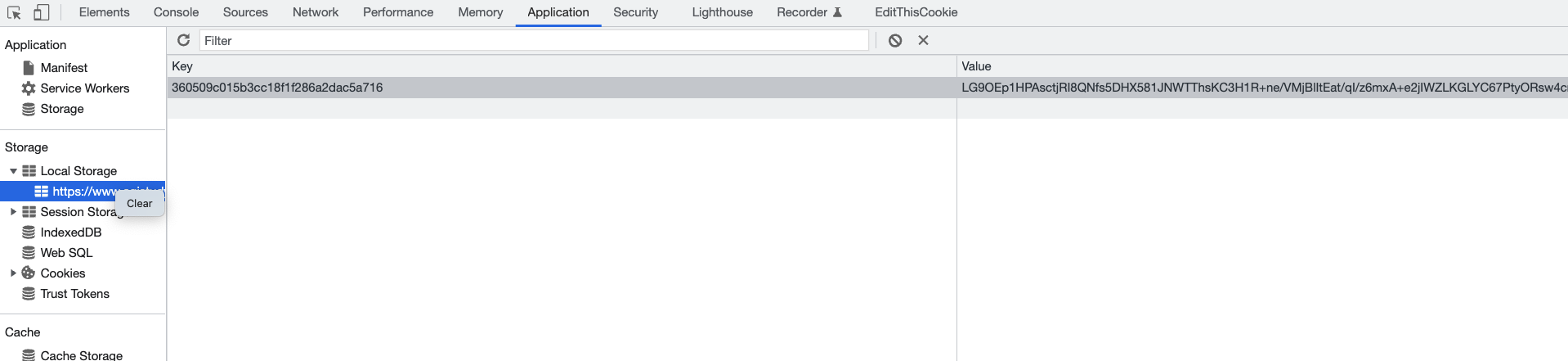
然后重新刷新页面,果然看到了XHR请求:

- 前面找不到的dUHTtbN9Om和dwDMxkUh0FG方法,在这个文件中找到了。我们利用JS文件中找到的这2个方法,解开php中两串神秘的代码:

第一段是反爬检测的代码。
第二段是数据解密的代码。
😶🌫️分析了这么多,是不是感觉有一点混乱,那我们理理头绪,看看这个JS文件与PHP文件的关系。数据获取在JS文件里面,先读本地缓存,如果有的话取本地缓存数据;如果没有的话,发送Ajax请求。无论是Ajax请求来的还是本地读取的数据,都是加密的,解密的算法放在JS文件里面,然后渲染到PHP页面上去,整个JS文件的入口在PHP文件里面。总结下来就是JS文件包含数据的加密(Ajax参数),解密(Ajax返回数据)和发送请求代码,PHP里则是存放JS的入口方法。
在分析的过程中有一点需要注意,这个网站大概几分钟会重新加载一次dom,这样混淆的代码名字又会变了,所以调试的时候将文件保存在本地,然后再进行分析。
最后说一下整个数据抓取的思路,首先请求php文件,然后通过正则匹配出php文件里面上面提到的那个加密解密的JS,执行JS里面的eval,得到实时的加密解密代码,然后用解密的代码去解密php文件里第二段的加密数据即可。
推荐一些练手的无限debugger网站
- aHR0cHM6Ly93d3cubm1wYS5nb3YuY24v
- 网址:aHR0cDovL3p3Zncuc2FuLWhlLmdvdi5jbi9pY2l0eS9pY2l0eS9ndWVzdGJvb2svaW50ZXJhY3Q=
接口:aHR0cDovL3p3Zncuc2FuLWhlLmdvdi5jbi9pY2l0eS9hcGktdjIvYXBwLmljaXR5Lmd1ZXN0Ym9vay5Xcml0ZUNtZC9nZXRMaXN0
- aHR0cHM6Ly9iei56enptaC5jbi9pbmRleA==
总结
本文介绍了常见的几种无限debugger的形式以及对应的几种解决方案。然后通过一个相对复杂的例子做了一个演示,这个网站通过检测浏览器高度,代码执行延迟来反调试,仔细阅读相关的代码我们还可以找到其对无头浏览器也做了检测,这样如果想用playwright之类的浏览器工具的话可能也会被检测到,而且请求的参数以及返回的数据也是做了动态的加密,总体而言反爬还是比较严的。本文的相关代码已经上传,关注公众号,回复关键字“代码 某气网”,即可获取案例完整代码。


