免责声明:本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
在很多情况下,我们可能需要在网页中自动执行某些复杂的代码,帮助我们完成一些操作。比如抢票,刷单,爬虫等。通常我们可以开发Chrome浏览器插件来实现这种功能,但是开发浏览器插件的话得先要去学习浏览器插件开发流程,原理等。有没有什么成本比较低的方式?有的,这里我们介绍的主角叫做 Tampermonkey,也叫油猴。这个插件的功能非常强大,利用它我们几乎可以在网页中执行任何 JavaScript 代码,实现我们想要的功能。同时,我们还可以将Tampermonkey 应用到 JavaScript 逆向分析中,去帮助我们更方便地分析一些 JavaScript 加密和混淆代码。
安装
打开Chrome 网上商店,搜索Tampermonkey,然后点击添加至Chrome即可。
添加完之后,点击浏览器右上角的扩展程序小图标,然后点击Tampermonkey的固定按钮,将Tampermonkey固定到菜单栏,方便以后使用。
使用
Tampermonkey 运行的是 JavaScript 脚本,每个网站都能有对应的脚本运行,不同的脚本能完成不同的功能。这些脚本我们可以自定义,同样也可以用已经写好的很多脚本,毕竟有些轮子有了,我们就不需要再去造了。下面列举一些油猴脚本免费使用的网站:
- Userscript.Zone Search:是一个新网站,允许通过输入合适的URL或域来搜索用户脚本。
Greasy Fork:最受欢迎的后起之秀,提供用户脚本的网站,可实现去掉视频播放广告,去水印等多种功能,可以直接安装使用,储存库中有大量的脚本资源。
OpenUserJS:继 GreasyFork 之后开始创办,在其储存库中也拥有大量的脚本资源 。
查看当前页面运行的脚本
浏览器地址输入某一网址,然后观察浏览器右上角Tampermonkey小图标
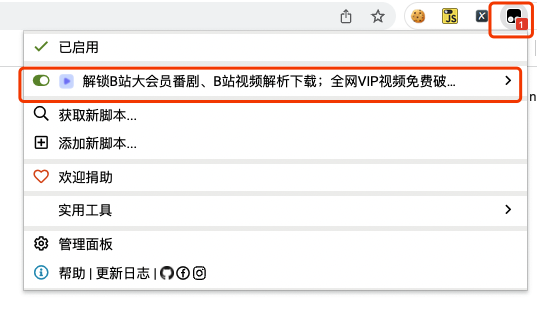
小图标上显示数字就是当前页面可以执行的脚本数量,点击这个图标进去可以看到具体执行的脚本,如上图。
管理脚本
点击浏览器右上角Tampermonkey小图标,然后点击管理面板。
然后可以看到我们已经添加的脚本:

我们可以在这个界面上对任意一个脚本控制开启与关闭,修改删除等。
我们也可以点击已安装脚本左边的+号来新建一个脚本:
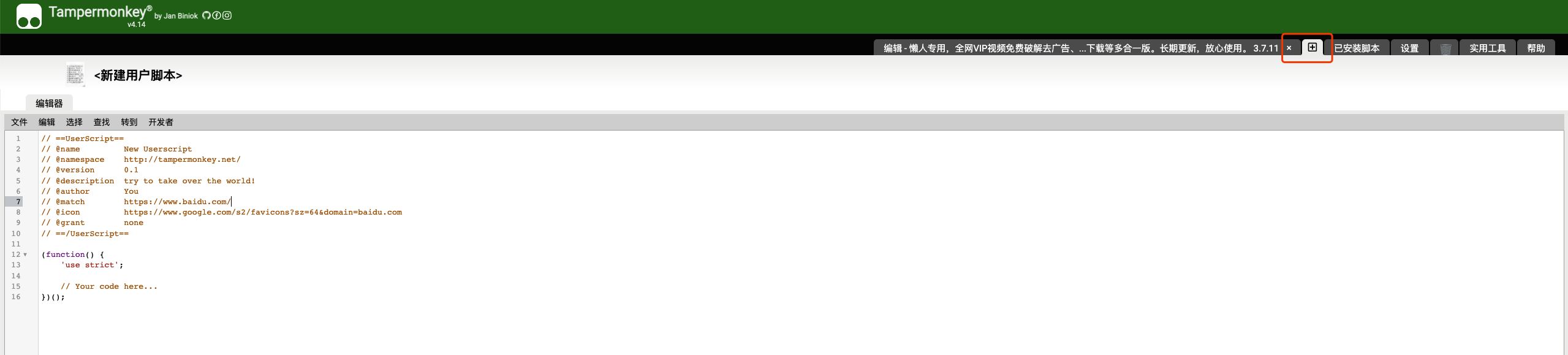
我们观察下脚本内容里的几个标注我们挑几个常用的来讲。
@name表示该脚本的名称
@include表示脚本生效的域名,可以配置多个,每个单独一行,支持通配符。比如匹配所有的http:@include http://*,匹配所有的https:@include https://*,也可以将2者合并用一个简单的写法: @include *。
@grant表示授予的权限,比如GM_download表示下载权限,GM_openInTab表示打开tab的权限,GM_xmlhttpRequest表示发起异步请求的权限,GM_cookie表示获取cookie的权限等等
@run-at确定了脚本的注入时机,在js逆向中也很重要。完整的脚本注释介绍如下:
| 属性名 | 作用 |
|---|---|
| @name | 油猴脚本的名字 |
| @namespace | 命名空间,用来区分相同名称的脚本,一般写成作者名字或者网址就可以了 |
| @version | 脚本版本,油猴脚本的更新会读取这个版本号 |
| @description | 描述,用来告诉用户这个脚本是干什么用的 |
| @author | 作者名字 |
| @match | 只有匹配的网址才会执行对应的脚本 |
| @grant | 指定脚本运行所需权限,如果脚本拥有相应的权限,就可以调用油猴扩展提供的API与浏览器进行交互。如果设置为none的话,则不使用沙箱环境,脚本会直接运行在网页的环境中,这时候无法使用大部分油猴扩展的API。如果不指定的话,油猴会默认添加几个最常用的API |
| @require | 如果脚本依赖其他js库的话,可以使用require指令,在运行脚本之前先加载其他库,常见用法是加载jquery,导库,和node差不多,相当于导入外部的脚本 |
| @run-at | 脚本注入时机,这个比较重要,有时候是能不能hook到的关键,document-start:网页开始时;document-body:body出现时;document-end:载入时或者之后执行;document-idle:载入完成后执行,默认选项 |
| @connect | 当用户使用GM_xmlhttpRequest请求远程数据的时候,需要使用connect指定允许访问的域名,支持域名、子域名、IP地址以及*通配符 |
| @updateURL | 脚本更新网址,当油猴扩展检查更新的时候,会尝试从这个网址下载脚本,然后比对版本号确认是否更新 |
我们自己创建一个脚本,内容如下:
1 | // ==UserScript== |
脚本命名为Any Hello world,然后可以匹配到任意的http或者https协议的页面,脚本内容比较简单,只是简单的在控制台输出了一下Hello, world。我们保存下,就可以看到多了一个脚本:

然后我们打开任意一个页面,比如百度的首页,同时打开开发者工具,可以看到控制台上正常输出:

一个简单的案例
网址:aHR0cDovL3F5eHkuc2NqZ2ouYmVpamluZy5nb3YuY24vaG9tZQ==
以某征信信息网站为例,我们抓包查看请求:
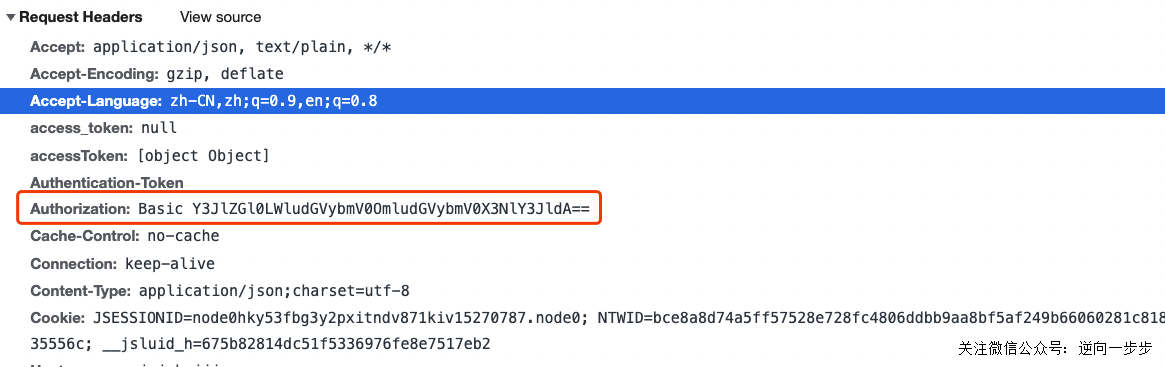
可以看到请求头带有Authorization这个验证参数,我们利用油猴来Hook这个参数,准备好要注入的JS,如下:

简单解释下代码,先用一个对象保存原来的XMLRequest对象的setRequestHeader方法,然后重写setRequestHeader方法加入自己的debug逻辑,最后调用原来的setRequestHeader方法。
刷新网页,发现成功断上了
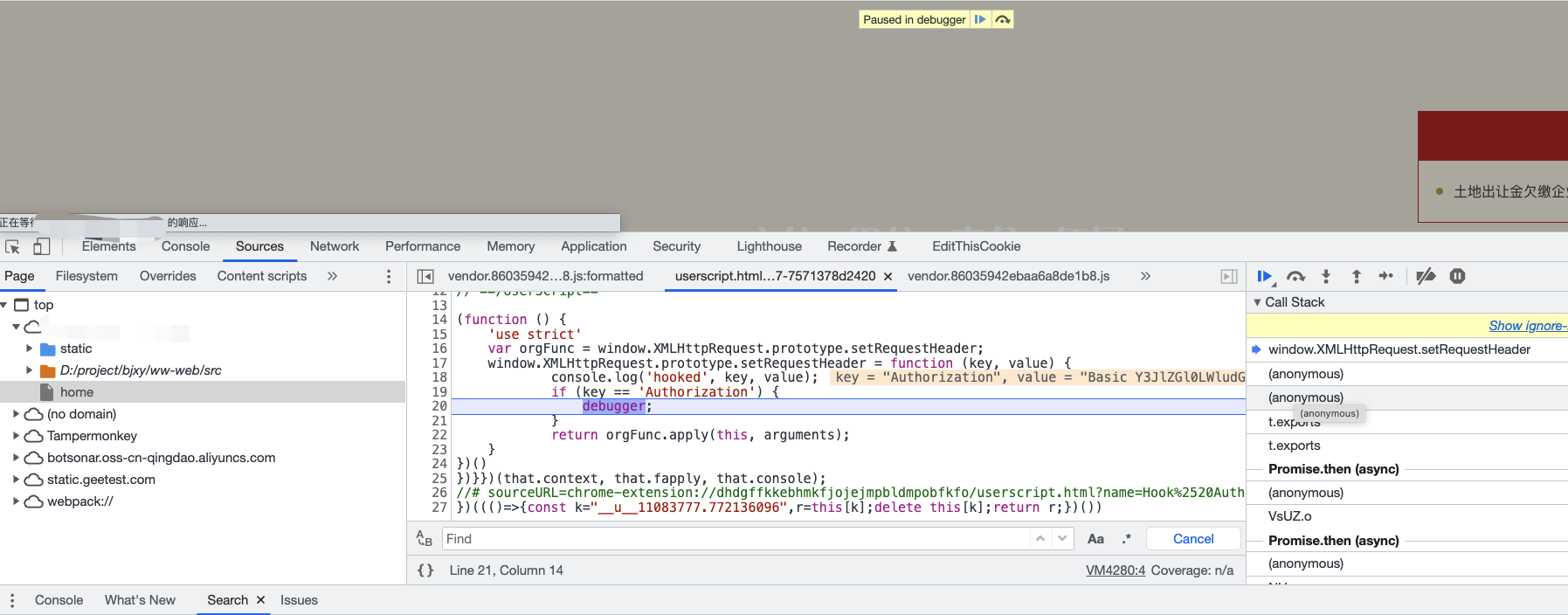
接着看下调用栈,进入单步调试,这里再介绍一个技巧,就是当调用栈很多的时候,从JS文件名称上可以看到一些文件压根不需要进去单步调试,这个时候我们可以选中该文件右键点击Add script to ignore list,如下图:
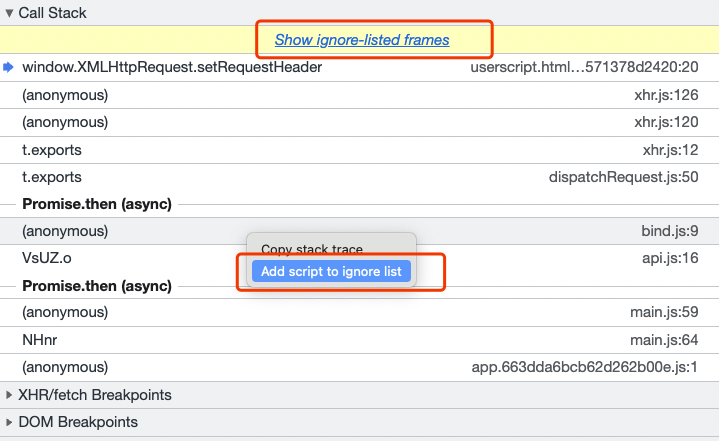
然后那些无关的文件就会被折叠起来,看上图有一个Show ignore-listed frames就是忽略的文件。可以看到这样调用栈就精简不少,从原先的几十个变成只有几个。我们一步步跟进去会发现未登录时,Authorization是写死的:
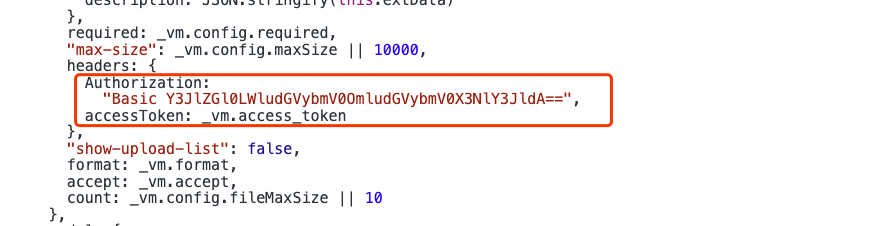
登录之后,Authorization的值是根据用户名和密码做的一个简单的Base64编码:


