免责声明:本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
前言 本文是机器过极验滑块验证码系列文章的第四篇,通过一个实际网站介绍如何利用逆向分析自动过极验滑块,极验滑块系列包含乱序底图还原,验证码w参数生成,补环境,利用像素点RGB差值获取缺口位置以及通过机器学习获取缺口位置。而极验滑块系列只是验证码系列的第一个系列,后边会罗列市面上常用的验证码,然后发文一一解决。
上一篇文章见:JS逆向案例——极验滑块验证码补环境
模拟登录天眼查 极验滑块验证码与登录接口的关系 网址:aHR0cHM6Ly93d3cudGlhbnlhbmNoYS5jb20v
以天眼查的登录为例,在进行滑块验证时,进行抓包分析。
在极验系列第一篇 JS逆向案例——极验滑块验证码底图还原 中,说过geetest的几个请求之间的关系,这里重新梳理一下,然后顺便梳理下geetest请求与天眼查登录接口的关系。如下图:
image-20220424224028967
可以看到每一次请求都是环环相扣,一共发起5次请求,下一次请求的入参或多或少都用到上一次请求的返回。
第一次请求 封装一个geetest_xhtml请求,用于获取challenge和gt,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import timeimport mathimport requestsdef geetest_xhtml (): cookies = { 'acw_sc__v2' : 'acw_sc__v2的值' } headers = { } json_data = { 'uuid' : math.floor(time.time() * 1000 ), } response = requests.post('https://www.tianyancha.com/verify/geetest.xhtml' , cookies=cookies, headers=headers, json=json_data) return response.text
cookie值里面仅仅需要一个acw_sc__v2,而acw_sc__v2的值是有时效性的,所以在实际生产中肯定也要逆向去动态生成这个cookie值,但是本文重点放在极验滑动验证码上,所以cookie直接拷贝,并没有细究cookie是如何生成的,后边有空了可以回过头了看看这个cookie是如何生成的。
运行结果如下:
image-20220425001609069
第二次请求 封装一个get_type请求,入参是第一个请求返回的gt,用正则匹配get_type返回的path和type,这两个值将在下一个请求中用到,由于这里只是做一个简单的演示,所以并未考虑程序的健壮性,写的有点糙,略略略。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def get_type (gt ): headers = { } params = { 'gt' : gt, 'callback' : f'geetest_{math.floor(time.time() * 1000 )} ' , } response = requests.get('https://api.geetest.com/gettype.php' , params=params, headers=headers) print (response.text) path = re.findall('\"path\": \"(.*?)\"' , response.text)[0 ] _type = re.findall('\"type\": \"(.*?)\"' , response.text)[0 ] return path, _type
代码运行结果如下:
image-20220425003036734
第三次请求 封装一个get请求,如参是第一次请求返回的gt和challenge以及第二次请求返回的type和path,该请求返回新的challenge(实际上在之前的challenge后边拼接了2个字符串),c,s,bg,fullbg。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def get (gt, challenge, _type, path): url = f"https://api.geetest.com/get.php?gt={gt}&challenge={challenge}&product=popup&offline=false&" \ f"protocol=https://&type={_type}&path={path}&callback=geetest_{math.floor(time.time() * 1000)}" headers = { 'authority' : 'api.geetest.com' , 'accept' : '*/*' , 'accept-language' : 'zh-CN,zh;q=0.9' , 'cache-control' : 'no-cache' , 'pragma' : 'no-cache' , 'referer' : 'https://www.tianyancha.com/' , 'sec-ch-ua' : '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"' , 'sec-ch-ua-mobile' : '?0' , 'sec-ch-ua-platform' : '"macOS"' , 'sec-fetch-dest' : 'script' , 'sec-fetch-mode' : 'no-cors' , 'sec-fetch-site' : 'cross-site' , 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36' , 'Cookie' : 'GeeTestAjaxUser=feae0be0cdd2042a5e570e9d3245e949; GeeTestUser=52dc984495fafeb0d018864b96edccd9' } response = requests.get (url, headers=headers) return response.text
运行结果如下:
image-20220425111939144
第四次请求 第四次请求需要滑块的轨迹,轨迹数组需要通过滑块缺口的差值来生成,要想计算滑块缺口的差值,需要还原滑块底图。
滑块底图还原 底图还原参考文章: JS逆向案例——极验滑块验证码底图还原
核心代码为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def restore_pic (pic_path, new_pic_path ): unordered_pic = Image.open (pic_path) ordered_pic = unordered_pic.copy() for i, d in enumerate (div_offset): im = unordered_pic.crop((math.fabs(d['x' ]), math.fabs(d['y' ]), math.fabs(d['x' ]) + 10 , math.fabs(d['y' ]) + 58 )) if d['y' ] != 0 : ordered_pic.paste(im, (10 * (i % (len (div_offset) // 2 )), 0 ), None ) else : ordered_pic.paste(im, (10 * (i % (len (div_offset) // 2 )), 58 ), None ) ordered_pic.save(new_pic_path)
缺口计算 缺口计算的方式基本上分2种,一种是图片处理,计算图片的每个像素点位置的色差去判断缺口;一种是通过深度学习去识别缺口位置。会专门出一篇文章计算这2种方式。这里先贴第一种方式的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def diff_rgb (rgb1, rgb2 ): return math.fabs(rgb1[0 ] - rgb2[0 ]) + math.fabs(rgb1[1 ] - rgb2[1 ]) + math.fabs(rgb1[2 ] - rgb2[2 ]) > 255 def get_moving_dst (complete_pic_path, incomplete_pic_path ): complete_pic = Image.open (complete_pic_path) incomplete_pic = Image.open (incomplete_pic_path) w, h = complete_pic.size for i in range (0 , w): for j in range (0 , h): complete_pic_pixel_rgb = complete_pic.getpixel((i, j)) incomplete_pic_pixel_rgb = incomplete_pic.getpixel((i, j)) if diff_rgb(complete_pic_pixel_rgb, incomplete_pic_pixel_rgb): return i return 0
生成轨迹数组 在网上找了一些轨迹算法,效果似乎不太好。就想着搭建一个本地的轨迹库,然后在实际使用的时候根据滑动距离从本地库中去拿。
具体思路是:
用Flask搭建一个轨迹收集服务
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 import jsonimport mathimport picklefrom flask import Flask, requestfrom flask_cors import cross_originapp = Flask(__name__) @app.post("/track" @cross_origin(supports_credentials=True , methods="*" , allow_headers="*" ) @cross_origin() def track (): tracks = pickle.load(open ("tracks.pkl" , "rb" )) d = json.loads(request.data.decode()) print (d) download_image(d['bg' ], "bg.png" ) download_image(d['fullbg' ], "fullbg.png" ) restore_pic("bg.png" , "new_bg.png" ) restore_pic("fullbg.png" , "new_fullbg.png" ) x = get_moving_dst("new_bg.png" , "new_fullbg.png" ) if tracks.get(x): tracks[x].append({'track' : d['track' ], 'g7z' : d['g7z' ]}) else : tracks[x] = [{'track' : d['track' ], 'g7z' : d['g7z' ]}] pickle.dump(tracks, open ("tracks.pkl" , "wb" )) return 'ok' def download_image (url, image_file ): with open (image_file, "wb" ) as f: f.write(requests.get(url).content) if __name__ == '__main__' : track_data = {} pickle.dump(track_data, open ("tracks.pkl" , "wb" )) app.run(host='0.0.0.0' , port=8088 )
先手动通过滑块验证100-200次,收集起来每一次g7z(g7z为实际滑动的距离)对应的轨迹方程。
使用
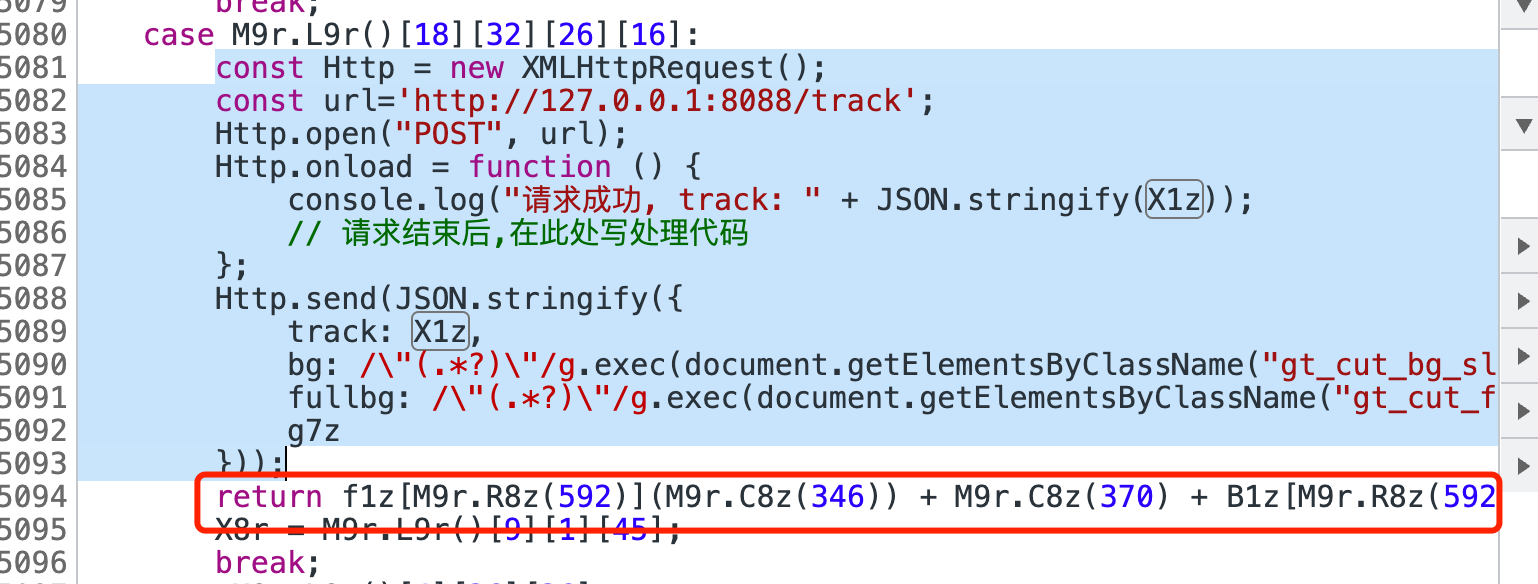
1 2 3 4 5 6 7 8 9 10 11 12 13 const Http = new XMLHttpRequest ();const url='http://127.0.0.1:8088/track' ;Http .open ("POST" , url);Http .onload = function ( console .log ("请求成功, track: " + JSON .stringify (X1z)); }; Http .send (JSON .stringify ({ track : X1z, bg : /\"(.*?)\"/g .exec (document .getElementsByClassName ("gt_cut_bg_slice" )[0 ].style .backgroundImage )[1 ], fullbg : /\"(.*?)\"/g .exec (document .getElementsByClassName ("gt_cut_fullbg_slice" )[0 ].style .backgroundImage )[1 ], g7z }));
在返回加密轨迹数组的之前去调用Flask服务,这样拿到的轨迹数组就是最终的轨迹数组,从而可以收集正确的轨迹数组。如下图:
image-20220428155854981
通过手动过滑块就可以把轨迹数组收集到tracks.pkl文件了。
生成w参数 w参数逆向分析与其服务搭建参考:JS逆向案例——极验滑块验证码w参数生成 和 JS逆向案例——极验滑块验证码补环境
鉴于我们早已经搭建好了w请求服务,这里直接调用接口就好了,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 def get_w (gt, challenge, tracks, c, s, v ): url = "http://127.0.01:8081/geetest/w" data = { "tracks" : json.dumps(tracks), "c" : json.dumps(c), "s" : s, "challenge" : challenge, "gt" : gt, "v" : v } response = requests.post(url, json=data) return response.json()
运行结果如下:
image-20220425153143590
进行滑块的验证 进行滑块验证的请求很简单:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def ajax (gt, challenge, w): url = f'https://api.geetest.com/ajax.php?gt={gt}&challenge={challenge}&w={w}&callback=geetest_{t}' headers = { 'authority' : 'api.geetest.com' , 'accept' : '*/*' , 'accept-language' : 'zh-CN,zh;q=0.9' , 'cache-control' : 'no-cache' , 'pragma' : 'no-cache' , 'referer' : 'https://www.tianyancha.com/' , 'sec-ch-ua' : '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"' , 'sec-ch-ua-mobile' : '?0' , 'sec-ch-ua-platform' : '"macOS"' , 'sec-fetch-dest' : 'script' , 'sec-fetch-mode' : 'no-cors' , 'sec-fetch-site' : 'cross-site' , 'user-agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36' , } response = requests.get (url, headers=headers) return response.text
就一个get请求,带上gt,challenge和w参数就行。
滑块验证的核心逻辑,主要调用前面写好的几个方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def main (tracks ): d = geetest_xhtml() gt = d['data' ]['gt' ] challenge = d['data' ]['challenge' ] path, _type = get_type(gt) m = get(gt, challenge, _type , path) url = "https://static.geetest.com/" unordered_complete_pic = urljoin(url, m['fullbg' ]) unordered_incomplete_pic = urljoin(url, m['bg' ]) with open ("image1.png" , "wb" ) as f: f.write(requests.get(unordered_complete_pic).content) with open ("image2.png" , "wb" ) as f: f.write(requests.get(unordered_incomplete_pic).content) restore_pic("image1.png" , "new_image1.png" ) restore_pic("image2.png" , "new_image2.png" ) dist = get_moving_dst("new_image1.png" , "new_image2.png" ) if tracks.get(dist): track = tracks[dist][0 ]['track' ] g7z = tracks[dist][0 ]['g7z' ] else : return w = get_w(m['gt' ], m['challenge' ], track, m['c' ], m['s' ], m['version' ], g7z) validator = ajax(w['gt' ], w['challenge' ], w['w' ]) print (validator)
运行结果:
image-20220428160923233
登录天眼查 别忘了我们这篇文章的最终目的是模拟登录天眼查,拿到滑块验证成功返回的validate之后,要请求天眼查的登录接口,先看下请求接口的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def login (mobile, password, challenge, validator ): cookies = { 'acw_sc__v2' : 'acw_sc__v2的值' , } headers = { } json_data = { 'mobile' : mobile, 'cdpassword' : password, 'loginway' : 'PL' , 'autoLogin' : False , 'type' : '' , 'challenge' : challenge, 'validate' : validator, 'seccode' : f'{validator} |jordan' , } response = requests.post('https://www.tianyancha.com/cd/login.json' , cookies=cookies, headers=headers, json=json_data) return response.text
就是一个post请求,没什么说的。
接着在主程序main方法的末尾加入调用这个login的代码:
1 2 3 4 if validator: validate = re.findall("\"validate\": \"(.*?)\"" , validator)[0 ] login_res = login('17777777777' , '202cb962ac59075b964b07152d234b70' , m['challenge' ], validate) return login_res
还是前面提到的,我们的主要目的放在极验验证上,所以这里cookie的acw_sc__v2值跟前面一样,复制下来就可,只不过这个cookie和第一个请求的cookie保持一致就行。另外,password也是一个加密的字符串,32位很符合md5码的特征,但是管它是啥呢?我们复制过来用就行。还有一点要注意的是,challenge要传get请求返回过来的,不要传第一个请求返回的。
程序运行的结果如下:
image-20220428163341351
提示密码错误,很显然,登录接口成功了。
总结 极验滑块的总算是成功了,暂时告一段落。我们是针对6.0.9这个版本的极验js文件进行的逆向,小版本的极验逻辑都差不多。大版本的可能区别会大一些,不过思路也差不多。极验的最新版本好像是4,后边会看看4这个大版本有什么不同。然后除了极验的滑块,还会试着看看能否搞定极验的点选与推理验证。
若需要代码,扫描加微信即可。
Last updated: 2023-05-23 15:17:59