免责声明:本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除!
逆向目标
目标:极验五子棋验证码逆向
接口:
逆向参数:
- Get Param
- captcha_id: 54088bb07d2df3c46b79f80300b0abbe
- challenge: e924d75f-7817-4ecc-9387-57eeefd060ce
- lot_number: 56076d56745d43489287d7465d4d0101
- payload: 太长,略
- process_token:太长,略
- w:太长,略
- Get Param
逆向过程
逆向过程基本上与消消乐与五子棋一致。说说不同的几点。
- 关于验证码加载接口
入参只有risk_type不一样,其余都一致。文字点选的risk_type为word,消消乐的为match,五子棋的是winlinze。接口返回的数据也基本一致,不同的是imgs对应的是点选验证码的底图,即要点击的图片,而ques这是要点击的文字的图片。如下图:
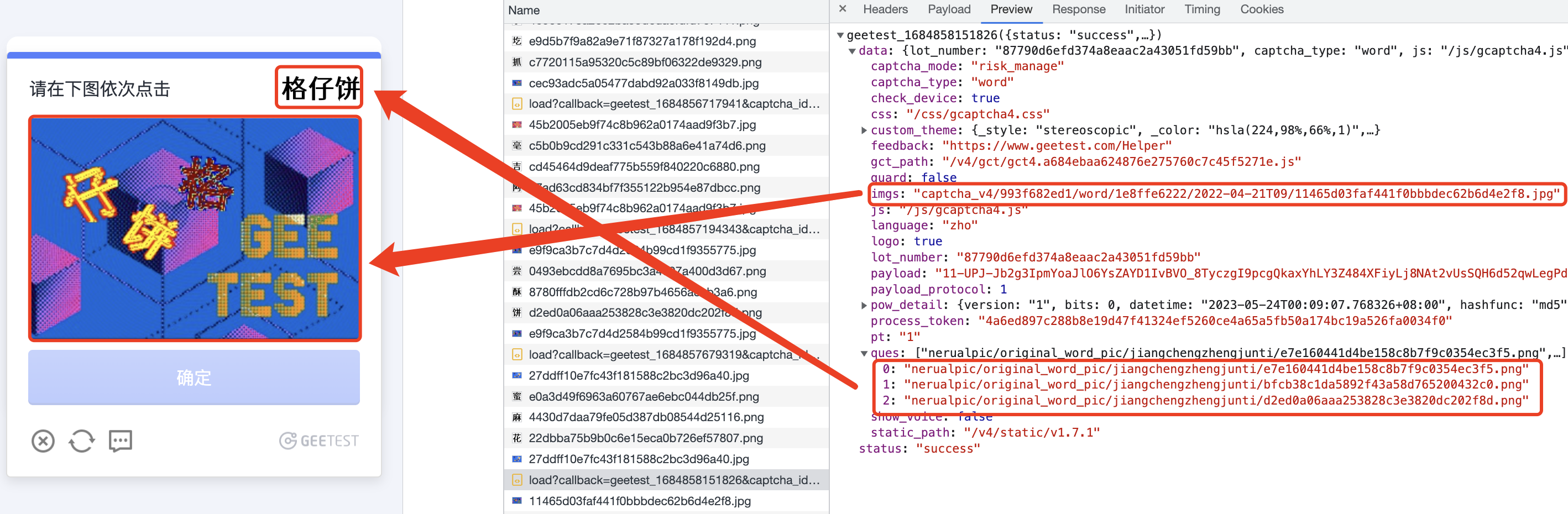
可以看到,ques中图片的顺序与要点击的文字的顺序一一对应。
- 关于验证码验证接口
入参完全一致,生成w参数的e对象结构也一致,如下图:
1 | { |
userresponse正是点击背景图上三个文字产生的坐标,但是这个坐标数值比较大,而实际的背景图大小是宽为300px,高为200px的,所以这个坐标肯定是经过处理的。
扒一扒userresponse的生成过程:
添加如下断点:
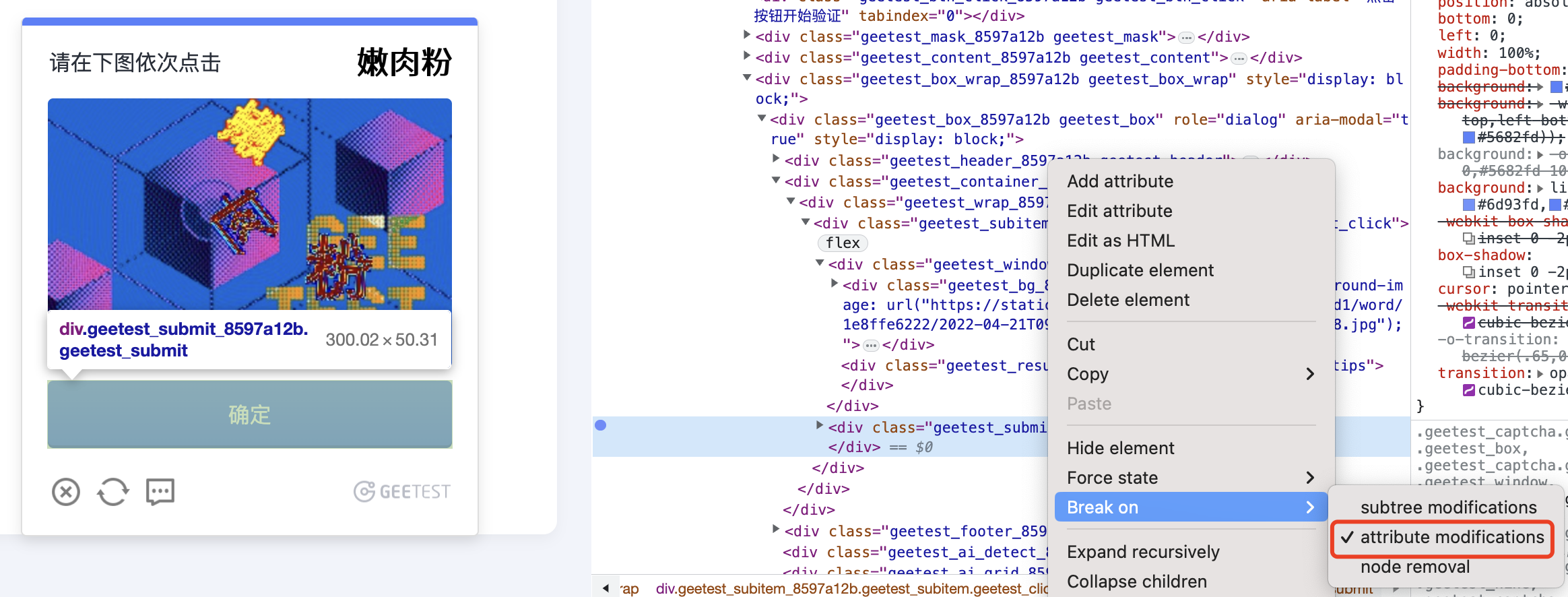
一路跟踪到这里:
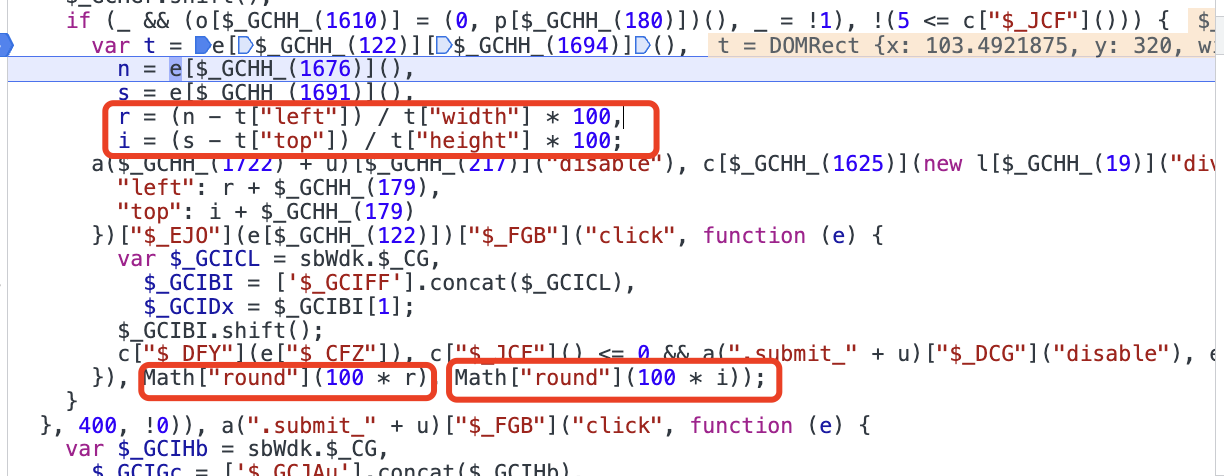
其中,t[left],t[top],t[width],t[height]都是固定值,分别为:103,320,300, 200。简单分析一下知,r和i分别是点击的位置坐标在整个背景图上的横纵坐标所占百分比,也即是某个汉字在整个背景图上横纵坐标的占比。最后,把这个百分比扩大100倍取整即可。
分析出来了userresponse坐标的生成过程,接下来就是文字点选最关键的目标检测与识别。
- 文字位置的检测与识别
首先是底图文字位置的检测,使用ddddocr库,代码如下:
1 | import ddddocr |
输出三个坐标,同时标记了验证码图片上文字的位置。
举例几张图片如下:
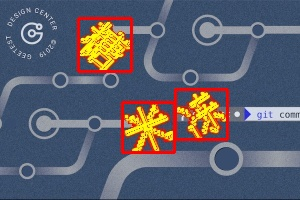
并输出坐标为:[[78, 18, 131, 71], [122, 102, 174, 152], [175, 89, 227, 139]]。
接下来就是文字识别,根据每个文字的四个顶点坐标把文字依次裁剪下来,代码如下:
1 | import cv2 |
得到的图片依次为:

然后再用ddddocr依次对其做文字识别:
1 | import ddddocr |
识别结果如下:
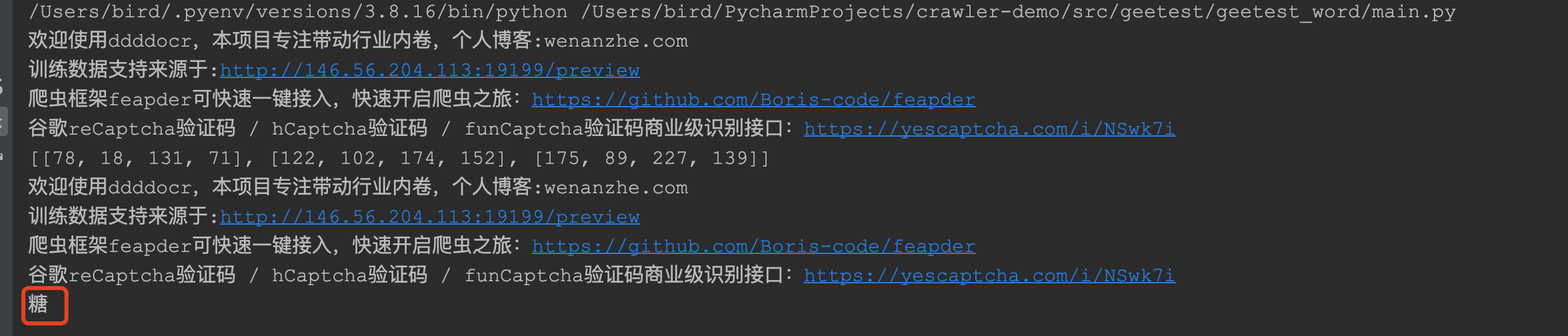
识别还是挺准确的。
除了底图的文字位置检测与识别,还有上边的标题需要识别,如下图:
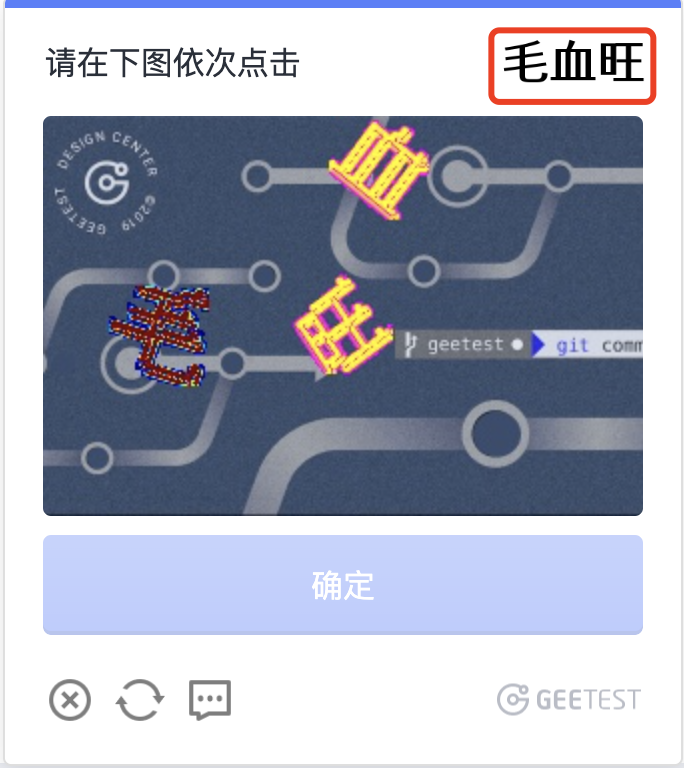
这些文字都是比较规整,并且同一个汉子的图片的md5的文件名基本上是不变的,大约只有400多个汉字,所以提前跑一个脚本,把它们收集起来即可。如下图:
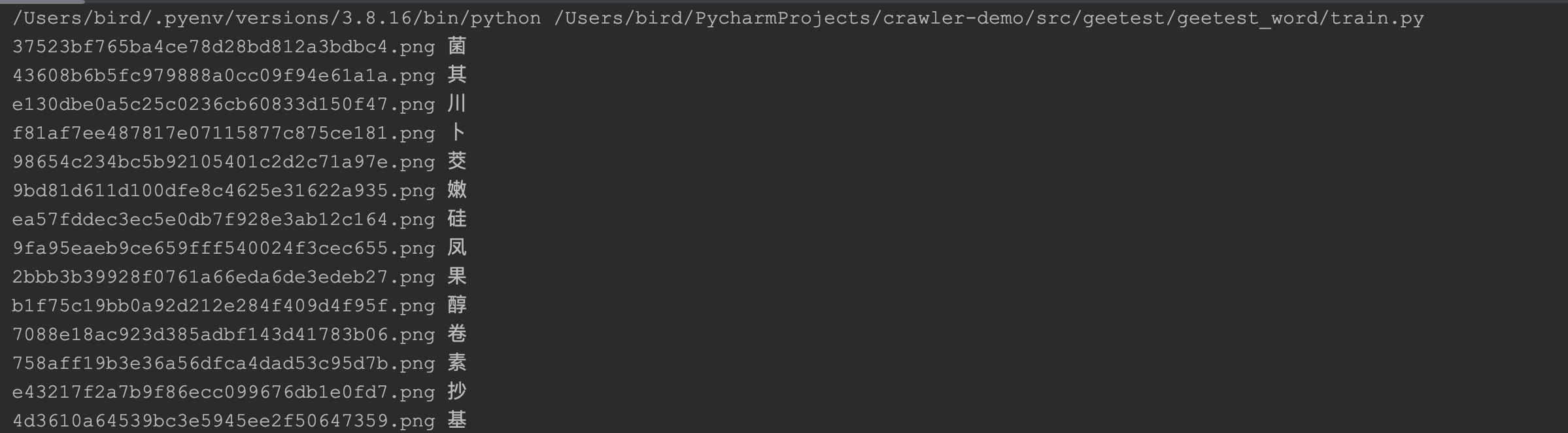
承载汉字的md5码名称的图片文件与汉字一一对应,并保存到data.pickle文件中。
运行与测试
运行与测试结果如下:

识别2个或者3个汉字,才能验证成功。通过测试可知,汉字的识别率还是挺低的,还是需要自己收集数据训练。后边会专门出一篇文章介绍自己训练这一块。
若需要完整代码,扫描加微信。